您的购物车目前是空的!
Stephen Wolfram《What Is ChatGPT Doing…and Why Does It Work》
前言
本书试图用第一性原理解释ChatGPT的工作原理, 以及它为何奏 效。 可以说这是一个关于技术的故事, 也可以说这是一个关千科学 的故事、 一个关于哲学的故事。 为了讲述这个故事, 我们必须汇集 数个世纪以来的一系列非凡的想法和发现。
看到自己长期以来感兴趣的众多事物一起得到突飞猛进的发展, 我 感到非常兴奋。 从简单程序的复杂行为到语言及其含义的核心特 征, 再到大型计算机系统的实用性, 所有这些都是ChatGPT故事 的一部分。
ChatGPT的基础是人工神经网络(本书中一般简称为神经网络或网 络), 后者最初是在20世纪40年代为了模拟理想化的大脑运作方 式而发明的。 我自己在1983年第一次编写出了一个神经网络, 但 它做不了什么有趣的事情。 然而40年后, 随着计算机的速度提高 上百万倍, 数十亿页文本出现在互联网上, 以及一系列重大的工 程创新, 情况已然大不相同。 出乎所有人意料的是, 一个比我在 1983年构建的神经网络大10亿倍的神经网络能够生成有意义的人 类语言, 而这在之前被认为是人类独有的能力。
本书包含我在 ChatGPT 问世后不久写的两篇长文。第一篇介绍了ChatGPT,并且解释了它为何拥有像人类一样的生成语言的能力。第二篇则展望了 ChatGPT 的未来,预期它能使用计算工具来做到人类所不能做到的事,特别是能够利用 Wolfram/Alpha 系统对知识进行计算(computational knowledge,在后文中简称为计算知识)的“超能力”。
虽然距离 ChatGPT 的发布仅过了三个月,我们也才刚刚开始了解它给我们的实际生活和思维能力可能带来的影响,但就目前而言,它的到来提醒我们,即使在已经发明和发现一切之后,仍有收获惊喜的可能。
斯蒂芬·沃尔弗拉姆 2023 年2 月28日
目录
第一篇 ChatGPT 在做什么?它为何能做到这些?
它只是一次添加一个词/ 概率从何而来 / 什么是模型 类人任务 (human-like task) 的模型 / 神经网络 / 机器学习和神经网/络的训练 /神经网络训练的实践和学问 / “足够大的神经网络当然无所不能! ” /“嵌入" 的概念 /ChatGPT 的内部原理 /ChatGPT 的训练 /在基础训练之外 / 真正让 ChatGPT 发挥作用的是什么 /意义空间和语义运动定律 / 语义语法和计算语言的力量 / 那么, ChatGPT 到底在做什么?它为什么能做到这些?
第二篇 利用 WolframlAlpha为ChatGPT 赋予计算知识超能力
ChatGPT和Wolfram!Alpha / 一个简单的例子 / 再举几个例子 / 前方的路
相关资源
第一篇 ChatGPT在做什么?它为何能做到这些?
它只是一次添加一个词
ChatGPT 可以自动生成类似于人类书写的文本, 这非常了不起, 也非常令人意外。 它是如何做到的呢?这为什么会奏效呢?我在这里将概述 ChatGPT 内部的工作方式, 然后探讨为什么它能够如此出色地产生我们认为有意义的文本。 必须在开头说明, 我会重点关注宏观的工作方式, 虽然也会提到一些工程细节, 但不会深入探讨。[这里提到的本质不仅适用于 ChatGPT, 也同样适用于当前的其他“大语言模型”(large language model, LLM)。]
首先需要解释, ChatGPT 从根本上始终要做的是,针对它得到的任何文本产生 “合理的延续"。 这里所说的 “合理” 是指, “人们在看到诸如数十亿个网页上的内容后, 可能期待别人会这样写”。
假设我们手里的文本是 “The best thing about Al is its ability to” (AI最棒的地方在于它能)。 想象一下浏览人类编写的数十亿页文本(比如在互联网上和电子书中), 找到该文本的所有实例, 然后看看接下来出现的是什么词, 以及这些词出现的概率是多少。ChatGPT 实际上做了类似的事情, 只不过它不是查看字面上的文本, 而是寻找在某种程度上 ”意义匹配" 的事物(稍后将解释)。
最终的结果是,它会列出随后可能出现的词及其出现的“概率” (按“概率”从高到低排列)。
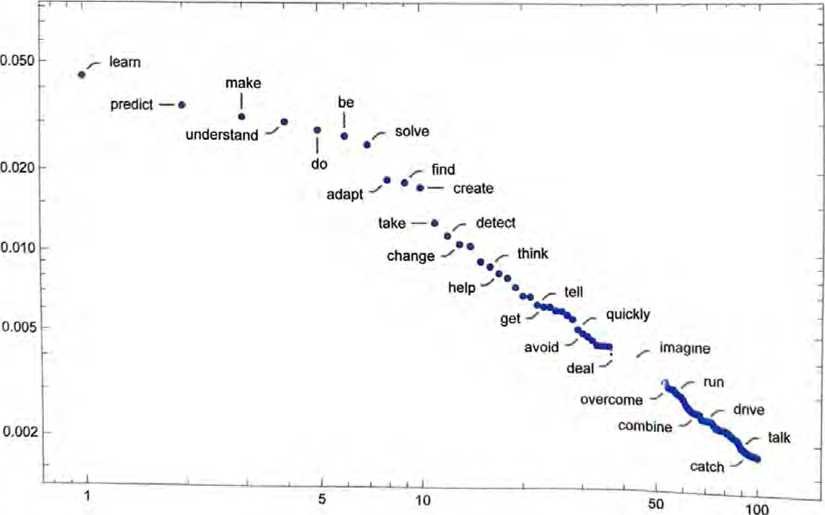
The best thing about AI is its ability to
| learn | 4.5% |
| predict | 3.5% |
| make | 3.2% |
| understand | 3.1% |
| do | 2.9% |
值得注意的是,当ChatGPT做一些事情,比如写一篇文章时,它实质上只是在一遍又一遍地询问“根据目前的文本,下一个词应该 是什么”,并且每次都添加一个词。[正如我将要解释的那样,更准 确地说,它是每次都添加一个“标记”(token),而标记可能只是 词的一部分。这就是它有时可以“造词”的原因。]
好吧,它在每一步都会得到一个带概率的词列表。但它应该选择 将哪一个词添加到正在写作的文章中呢?有人可能认为应该选择 “排名最高”的词,即分配了最高“概率”的词。然而,这里出现 了一点儿玄学(voodo,巫术)的意味。出于某种原因一也许有一天能用科学解释——如果我们总是选择排名最高的词,通常会得到一篇非常“平淡”的文章,完全显示不出任何“创造力”〔有时甚至会一字不差 地重复前文〕。但是,如果有时(随机)选择排名较低的词,就会 得到一篇“更有趣”的文章。
这里存在随机性意味着,如果我们多次使用相同的提示(prompt),每次都有可能得到不同的文章。而且,符合玄学思想的是,有一个 所谓的“温度”参数来确定低排名词的使用频率。对于文章生成 来说,“温度”为0.8似乎最好。(值得强调的是,这里没有使用任 何“理论”,“温度”参数只是在实践中被发现有效的一种方法。例 如,之所以采用“温度”的概念,是因为碰巧使用了在统计物理学中很常见的某种指数分布[玻尔兹曼分布],但它与物理学之间并没有任何实际联系,至少就我们目前所知是这样的。)
在进入下一节之前,需要解释一下,为了方便阐述,我在大多数情 况下不会使用ChatGPT中的完整系统,而是使用更简单的GPT-2 系统,它的优点是足够小,可以在标准的台式计算机上运行。因 此,对于书中展示的所有原理,我都能附上明确的Wolfram语言代码,你可以立即在自己的计算机上运行。
例如,通过以下方式可以获得前页列出的概率表。首先,需要检索底层的“语言模型”。

稍后,我们将深入了解这个神经网络,并谈谈它的工作原理。现在,我们可以把这个“网络模型”当作黑盒,应用到之前的文本中,并询问模型哪5个词紧随其后的概率最高。
in[ ]:= model[“The best thing about Al is its ability to”, {“TopProbabilities”, 5}]
out[ ]={do → 0.0288508, understand → 0.0307805, make → 0.0319072, predict → 0.0349748, learn → 0.0445305}
如下获取结果并将其转换为明确格式化的“数据集”。
in[ ]:=Dataset[ReverseSort[Association[%]], ItemDisplayFunction→(PercentForm[#,2]&)]
Out[ ]:=
| learn | 4.5% |
| predict | 3.5% |
| make | 3.2% |
| understand | 3.1% |
| do | 2.9% |
如果反复“应用模型”,在每一步都添加概率最高的词[在此代码 中指定为模型所做的“决策”(decision)],则会发生以下情况。
in[ ]:=NestList[StringJoin[# , model[# , “Decision”]] &, “The best thing about Al is its ability to”, 7]
out[ ]= {The best thing about Al is its ability to,
The best thing about Al is its ability to learn,
The best thing about Al is its ability to learn from,
The best thing about Al is its ability to learn from experience,
The best thing about Al is its ability to learn from experience.,
The best thing about Al is its ability to learn from experience. It,
The best thing about Al is its ability to learn from experience. It’s,
The best thing about Al is its ability to learn from experience. It’s not}
如果继续下去呢?在此(“零温度”[温度参数为0,即选择按概率排名最高的词])情况下,文本很快就会变得混乱和重复。
The best thing about Al is its ability to learn from experience.
It’s not just a matter of learning from experience, it’s learning from the
world around you. The Al is a very good example of this. It’s a very good example of how to use Al to improve your life. It’s a very good example of
how to use Al to improve your life. The Al is a very good example of how
to use Al to improve your life. It’s a very good example of how to use Al to
但是,如果我们不总是选择“排名最高”的词,而是有时随机选择“非排名最高”的词(通过将“温度”参数从0调高到0.8来获得这种随机性)呢?我们同样可以构建文本:
{The best thing about Al is its ability to,
The best thing about Al is its ability to create,
The best thing about Al is its ability to create worlds,
The best thing about Al is its ability to create worlds that,
The best thing about Al is its ability to create worlds that are,
The best thing about Al is its ability to create worlds that are both,
The best thing about Al is its ability to create worlds that are both exciting,
The best thing about Al is its ability to create worlds that are both exciting,}
每次执行此操作时,都会进行不同的随机选择,文本也会不同,就 像这5个例子一样。
The best thing about Al is its ability to learn. I’ve always liked the
The best thing about Al is its ability to really come into your world and just
The best thing about Al is its ability to examine human behavior and the way it
The best thing about Al is its ability to do a great job of teaching us
The best thing about Al is its ability to create real tasks, but you can
值得指出的是,即使在(温度为0.8的)第一步,也有许多可能的“下一个词”可供选择,尽管它们的概率迅速减小(是的,如下面的对数图所示,点的连线对应于,n-1次幂律衰减,这是语言的一般统计特征)。
如果再继续下去会发生什么呢?下面是一个随机的例子。虽然比选 择排名最髙的词(零温度)的情况好,但还是有点奇怪。
The best thing about Al is its ability to see through, and make sense of, the world around us, rather than panicking and ignoring. This is known as Al “doing its job” or Al “run-of-the-mill.” Indeed, taking an infinite number of steps, developing a machine that can be integrated with other systems, or controlling one system that’s truly a machine, is one of the most fundamental processes of Al. Aside from the human -machine interaction, Al was also a big part of creativity
这是使用最简单的GPT-2模型(发布于2019年)完成的。使用更新更大的GPT-3模型,结果会更好。下面是在提示相同但使用最大的GPT-3模型的情况下生成的零温度文本。
The best thing about Al is its ability to automate processes and make decisions quickly and accurately. Al can be used to automate mundane tasks, such as data entry, and can also be used to make complex decisions, such as predicting customer behavior or analyzing large datasets. Al can also be used to improve customer service, as it can quickly and accurately respond to customer inquiries. Al can also be used to improve the accuracy of medical diagnoses and to automate the process of drug discovery.
下面是一个温度为0.8的随机示例。
The best thing about Al is its ability to learn and develop over time, allowing it to continually improve its performance and be more efficient at tasks. Al can also be used to automate mundane tasks, allowing humans to focus on more important tasks. Al can also be used to make decisions and provide insights that would otherwise be impossible for humans to figure out.
概率从何而来
ChatGPT总是根据概率选择下一个词,但是这些概率是从何而来的 呢?让我们从一个更简单的问题开始:考虑逐字母(而非逐词)地 生成英文文本。怎样才能计算出每个字母应当出现的概率呢?
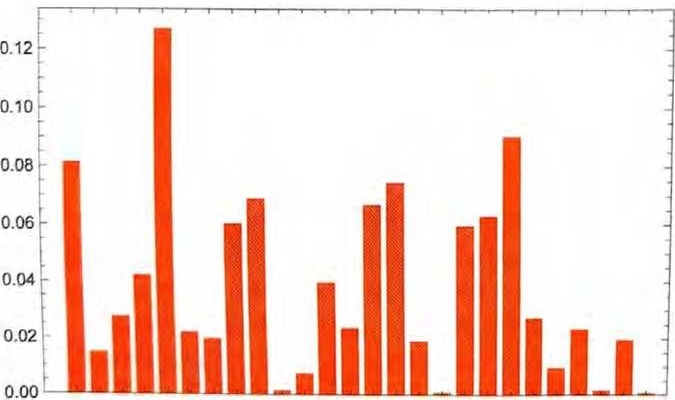
我们可以做一件很小的事,拿一段英文文本样本,然后计算其中不 同字母的出现次数。例如,下面的例子统计了维基百科上“cats” (猫)的条目中各个字母的出现次数。

对“dogs”(狗)的条目也做同样的统计。

结果有些相似,但并不完全一样。(毫无疑问,在”dogs”的条目中,字母o更常见,毕竟dog—词本身就含有o。)不过,如 果我们采集足够大的英文文本样本,最终就可以得到相当一致的结果。

这是在只根据这些概率生成字母序列时得到的样本。

我们可以通过添加空格将其分解成“词”,就像这些“词”也是具有一定概率的字母一样。
还可以通过强制要求“词长”的分布与英文中相符来更好地造“词”。
ni hilwhuei kjtn isjd erogofnr n rwhwfao rcuw lis fahte uss cpnc nlu oe nusaetat llfo oeme rrhrtn xdses ohm oa tne ebedcon oarvthv ist
虽然并没有碰巧得到任何“实际的词”,但结果看起来稍好一些了。 不过,要进一步完善,我们需要做的不仅仅是随机地挑选每个字母。举例来说,我们知道,如果句子中有一个字母q,那么紧随其 后的下一个字母几乎一定是u。
以下是每个字母单独出现的概率图。
下图则显示了典型英文文本中字母对[二元(2-gram或bigram)字母]的概率。可能出现的第一个字母横向显示,第二个字母纵向显示。
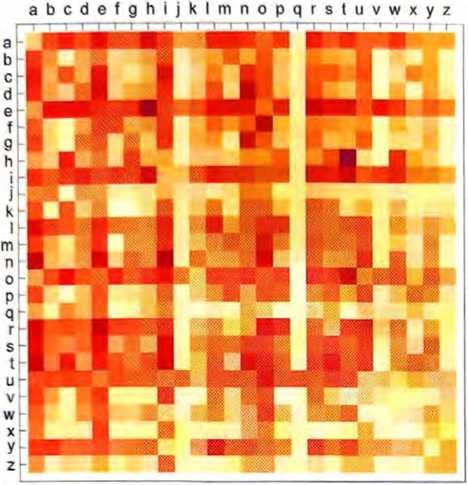
可以看到,q列中除了u行以外都是空白的(概率为零)。现在不再一次一个字母地生成“词”,而是使用这些二元字母的概率,一 次关注两个字母。下面是可以得到的一个结果,其中恰巧包括几个“实际的词”。
on inguman men ise forernoft weat iofobato buc ous corew ousesetiv fa lie tinouco ryefo ra the ecederi pasuthrgr cuconom tra tesla will tat pere thi
有了足够多的英文文本,我们不仅可以对单个字母或字母对(二元字母)得到相当好的估计,而且可以对更长的字母串得到不错的估计。如果使用逐渐变长的n元(n-gram)字母的概率生成“随机的词”,就能发现它们会显得越来越“真实”。
| 0 | on gxeeetowmt tsifhy ah aufnsoc ior oia itlt bnc tu ih uls |
| 1 | ri io os ot timumumoi gymyestit ate bshe abol viowr wotybeat mecho |
| 2 | wore hi usinallistin Ilia ale warou pothe of premetra beet upo pr |
| 3 | qual musin was witherins wil por vie surgedygua was suchinguary outheydays theresist |
| 4 | stud made yello adenced through theirs from cent intous wherefo proteined screa |
| 5 | special average vocab consumer market prepara injury trade consa usually speci utility |
现在假设——多少像ChatGPT所做的那样——我们正在处理整个词,而不是字母。英语中有大约50000个常用词。通过查看大型的英文语料库(比如几百万本书,总共包含几百亿个词),我们可以估计每个词的常用程度。使用这些信息,就可以开始生成“句子”了,其中的每个词都是独立随机选择的,概率与它们在语料库 中出现的概率相同。以下是我们得到的一个结果。
of program excessive been by was research rate not here of of other is men were against are show they the different the half the the in any were leaved
毫不意外,这没有什么意义。那么应该如何做得更好呢?就像处理 字母一样,我们可以不仅考虑单个词的概率,而且考虑词对或更长的n元词的概率。以下是考虑词对后得到的5个结果,它们都是从 单词cat开始的。
cat through shipping variety is made the aid emergency can the
cat for the book flip was generally decided to design of
cat at safety to contain the vicinity coupled between electric public
cat throughout in a confirmation procedure and two were difficult music
cat on the theory an already from a representation before a
结果看起来稍微变得更加“合理”了。可以想象,如果能够使用足 够长的n元词,我们基本上会“得到一个ChatGPT”,也就是说, 我们得到的东西能够生成符合“正确的整体文章概率”且像文章一 样长的词序列。但问题在于:我们根本没有足够的英文文本来推断 出这些概率。
在网络爬取结果中可能有几千亿个词,在电子书中可能还有另外 几百亿个词。但是,即使只有4万个常用词,可能的二元词的数 量也已经达到了16亿,而可能的三元词的数错则达到了 60万亿。 因此,我们无法根据已有的文本估计所有这些三元词的概率。当 涉及包含20个词的“文章片段”时,可能的20元词的数量会大 于宇宙中的粒子数量,所以从某种意义上说,永远无法把它们全 部写下来。
我们能做些什么呢?最佳思路是建立一个模型,让我们能够估计序列出现的概率——即使我们从未在已有的文本语料库中明确看到过这些序列。ChatGPT的核心正是所谓的“大语言模型”,后者已经 被构建得能够很好地估计这些概率了。
什么是模型
假设你想(像16世纪末的伽利略一样)知道从比萨斜塔各层掉落 的炮弹分别需要多长时间才能落地。当然,你可以在每种情况下 进行测量并将结果制作成表格。不过,你还可以运用理论科学的本 质:建立一个模型,用它提供某种计算答案的程序,而不仅仅是在 每种情况下测量和记录。
假设有一些(理想化的)数据可以告诉我们炮弹从斜塔各层落地所需的时间。
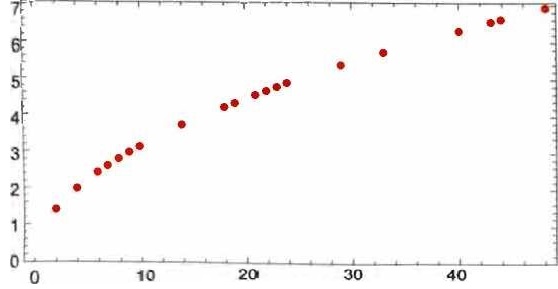
如何计算炮弹从一个没有明确数据的楼层落地需要多长时间呢?在这种特定情况下,可以使用已知的物理定律来解决问题。但是,假 设我们只有数据,而不知道支配它的基本定律。那么我们可能会做出数学上的猜测,比如也许应该使用一条直线作为模型。
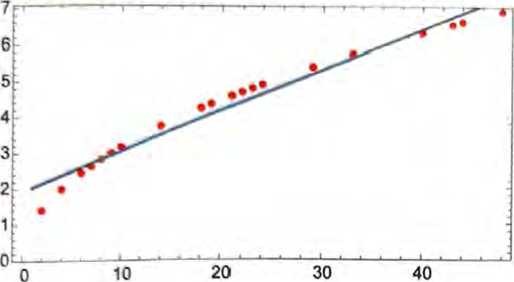
虽然我們可以选择不同的直线,但是上图中的这条直线平均而言最 接近我们拥有的数据。根据这条直线,可以估计炮弹从任意一层落 地的时间。
我们怎么知道要在这里尝试使用直线呢?在某种程度上说,我们并 不知道。它只是在数学上很简单,而且我们已经习惯了许多测量数 据可以用简单的数学模型很好地拟合。还可以尝试更复杂的数学模 型,比如a+bx+cx2,能看到它在这种情况下做得更好。
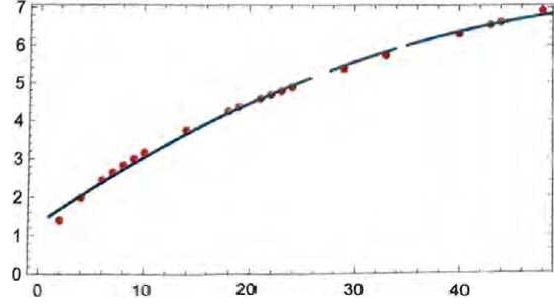
不过,这也可能会出大问题。例如,下面是我们使用a+b/x+c·sinx似 能得到的最好结果。
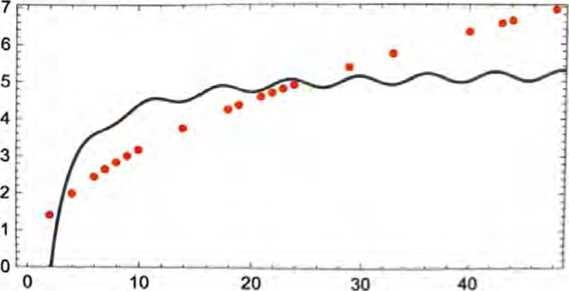
必须理解,从来没有“无模型的模型”。你使用的任何模型都有某种特定的基本结构,以及用于拟合数据的一定数量的“旋钮”(也就是可以设置的参数)。ChatGPT使用了许多这样的“旋钮”——实际上有1750亿个。
但是值得注意的是,ChatGPT的基本结构——“仅仅”用这么少的参数一足以生成一个能“足够好”地计算下一个词的概率的模型,从而生成合理的文章。
类人任务(human-like task)的模型
上文提到的例子涉及为数值数据建立模型,这些数据基本上来自简 单的物理学——几个世纪以来,我们已经知道可以用一些“简单的数学工具”为其建模。但是对于ChatGPT,我们需要为人脑产生的人类语言文本建立模型。而对于这样的东西,我们(至少目前)还 没有“简单的数学”可用。那么它的模型可能是什么样的呢?
在讨论语言之前,让我们谈谈另一个类人任务:图像识别。一个简 单的例子是包含数字的图像(这是机器学习中的一个经典例子)。

我们可以做的一件事是获取每个数字的大量样本图像。

要确定输入的图像是否对应于特定的数字,可以逐像素地将其与已有的样本进行比较。但是作为人类,我们似乎肯定做得更好:
因为即使数字是手写的,有各种涂抹和扭曲,我们也仍然能够识别它们。
当为上一节中的数值数据建立模型时,我们能够在取得给定的数值x之后,针对特定的a和b来计算出a+bx。那么,如果我们将图像中每个像素的灰度值视为变量xi,是否存在涉及所有这些变量 的某个函数,能(在运算后)告诉我们图像中是什么数字?事实证明,构建这样的函数是可能的。不过难度也在意料之中,一个典型 的例子可能涉及大约50万次数学运算。
最终的结果是,如果我们将一个图像的像素值集合输入这个函数, 那么输出将是一个数,明确指出该图像中是什么数字。稍后,我们将讨论如何构建这样的函数,并了解神经网络的思想。但现在,让我们先将这个函数视为黑盒,输入手写数字的图像(作为像素值的数组),然后得到它们所对应的数字。
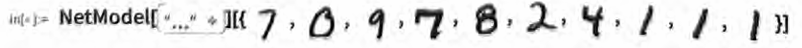
Out[ ]:= {7,0,9,7,8,2,4,1,1,1}
这里究竟发生了什么?假设我们逐渐模糊一个数字。在一小段时间内,我们的函数仍然能够“识别”它,这里为2。但函数很快就无法准确识别了,开始给出“错误”的结果。
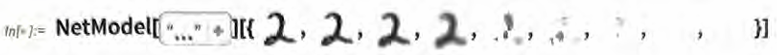
Out[ ]:= {2, 2, 2,1,1,1,1,1,1}
为什么说这是“错误”的结果呢?在本例中,我们知道是通过模糊 数字2来得到所有图像的。但是,如果我们的目标是为人类在识别图像方面的能力生成一个模型,真正需要问的问题是:面对一个模 糊的图像,并且不知道其来源,人类会用什么方式来识别它?
如果函数给出的结果总是与人类的意见相符,那么我们就有了一个“好模型”。一个重大的科学事实是,对于图像识别这样的任务,我们现在基本上已经知道如何构建不错的函数了。
能“用数学证明”这些函数有效吗?不能。因为要做到这一点,我们必须拥有一个关于人类所做的事情的数学理论。如果改变2的图 像中的一些像素,我们可能会觉得,仍应该认为这是数字2。但是 随着更多像素发生改变,我们又应该能坚持多久呢?这是一个关于 人类视觉感知的问题。没错,对于蜜蜂或章鱼的图像,答案无疑会 有所不同,而对于虚构的外星人的图像,答案则可能会完全不同。
神经网络
用于图像识别等任务的典型模型到底是如何工作的呢?目前最受欢迎而且最成功的方法是使用神经网络。神经网络发明于20世纪40 年代——它在当时的形式与今天非常接近——可以视作对大脑工作机制的简单理想化。
人类大脑有大约1000亿个神经元(神经细胞),每个神经元都能 够产生电脉冲,最高可达每秒约1000次。这些神经元连接成复杂 的网络,每个神经元都有树枝状的分支,从而能够向其他数千个神 经元传递电信号。粗略地说,任意一个神经元在某个时刻是否产生 电脉冲,取决于它从其他神经元接收到的电脉冲,而且神经元不同 的连接方式会有不同的“权重”贡献。
当我们“看到一个图像”时,来自图像的光子落在我们眼睛后面的 (光感受器)细胞上,它们会在神经细胞中产生电信号。这些神经细胞与其他神经细胞相连,信号最终会通过许多层神经元。在此过 程中,我们“识别”出这个图像,最终“形成”我们“正在看数字 2”的“想法”(也许最终会做一些像大声说出“二”这样的事情)。
上一节中的“黑盒函数”就是这样一个神经网络的“数学化”版 本。它恰好有11层(只有4个“核心层”)。

我们对这个神经网络并没打明确的“理论解释”,它只是在1998年 作为一项工程被构述出来的,而且被发现可以奏效。(当然,这与把我们的大脑描述为通过生物进化过程产生并没有太大的区别。)
好吧,但是这样的神经网络是如何“识别事物”的呢?关键在于吸引子(attractor)的概念。假设我们有手写数字1和2的图像。

我们希望通过某种方式将所有的1 “吸引到一个地方”,将所有的 2 “吸引到另一个地方”。换句话说,如果一个图像“更有可能是1” 而不是2,我们希望它最终出现在“1的地方”,反之亦然。
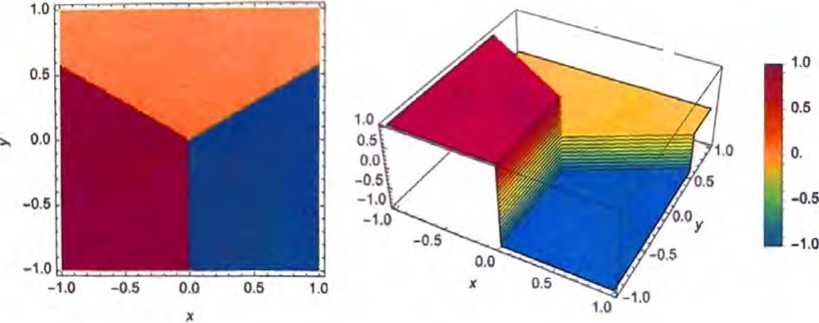
让我们做一个直白的比喻。假设平面上有一些位置,用点表示(在实际生活场景中,它们可能是咖啡店的位置然后我们可以想象,自己从平面上的任意一点出发,并且总是希望最终到达最近的点(即我们总是去最近的咖啡店)。可以通过用理想化的“分水岭”将平面分隔成不同的区域〈“吸引子盆地”〉来表示这一点。
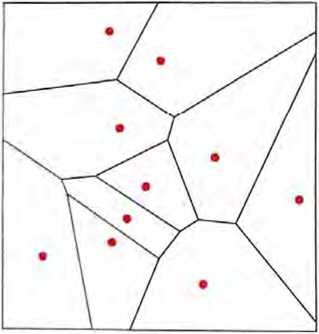
我们可以将这看成是执行一种“识别任务”,所做的不是识别一个 给定图像“看起来最像”哪个数字,而是相当直接地看出哪个点距 离给定的点最近。[这里展示的沃罗诺伊图将二维欧几里得空间中的点分隔开来。可以将数字识别任务视为在做一种非常类似的操作——只不过是在由每个图像中所有像素的灰度形成的784维空间中。]
那么如何让神经网络“执行识别任务”呢?让我们考虑下面这个非 常简单的情况。
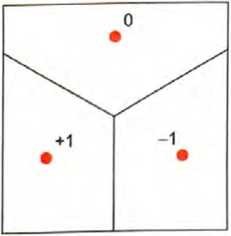
我们的目标是接收一个对应于位置{x,y}的输入,然后将其“识别”为最接近它的三个点之一。换句话说,我们希望神经网络能够计算出一个如下图所示的关于{x,y}的函数。
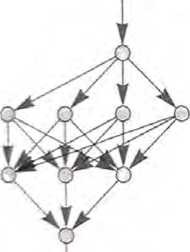
如何用神经网络实现这一点呢?归根结底,神经网络是由理想化的 “神经元”组成的连接集合——通常是按层排列的。一个简单的例子如下所示。
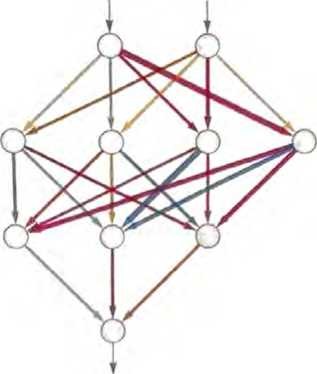
每个“神经元”都被有效地设置为计算一个简单的数值函数。为 了“使用”这个网络,我们只需在顶部输入一些数(像我们的坐标x和y),然后让每层神经元“计算它们的函数的值”并在网络中将 结果前馈,最后在底部产生最终结果。
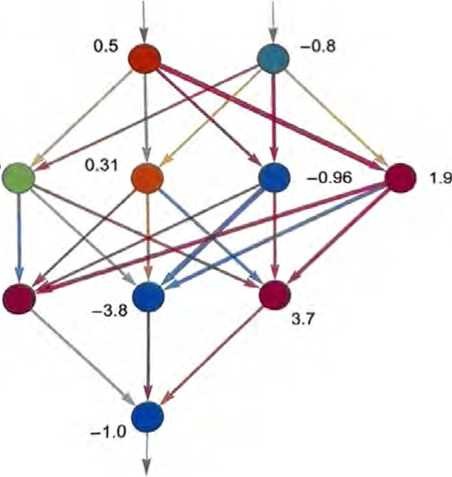
在传统(受生物学启发)的设置中,每个神经元实际上都有一些来 自前一层神经元的“输入连接”,而且每个连接都被分配了一个特 定的“权重”(可以为正或为负)。给定神经元的值是这样确定的: 先分别将其“前一层神经元”的值乘以相应的权重并将结果相加, 然后加上一个常数,最后应用一个“阈值”(或“激活”)函数。用 数学术语来说,如果一个神经元有输入x={x1,x2,…},那么我们要计算f[w·x+b]。对于权重w和常量b,通常会为网络中的每个 神经元选择不同的值;函数7则通常在所有神经元中保持不变。
计算w·x+b需要进行矩阵乘法和矩阵加法运算。激活函数f则使用了非线性函数(最终会导致非平凡的行为)。下面是一些常用的激活函数,这里使用的是Ramp(或ReLU)。

对于我们希望神经网络执行的每个任务〈或者说,对于我们希望它计算的每个整体函数〉,都有不同的权重选择。(正如我们稍后将讨论的那样,这些权重通常是通过利用机器学习根据我们想要的输出的示例“训练”神经网络来确定的。) 最终,每个神经网络都只对应于某个整体的数学函数,尽管写出来 可能很混乱。对于上面的例子,它是
w511 f(w311f(b11 +xw111 + yw112) + w312f(b12+xw121+yw122) +w313f(b13 +xw131 +yw132) + w314f(b14 +xw141 +yw142) + b31) +w512f(w321f(b11 + xw111 + yw112) + w322f(b12+xw121 +yw122) +w323f(b13+xw131 +yw132) + w324f(b14+xw141+yw142) + b32) +w513f(w331 f(b13+ xw111 +yw112) +w332f(b12+xw121 + yw122) +w333 f(b13+ xw131 + yw132) +w334f(b14 + xw141 + yw142) + b33) +b51
同样,ChatGPT的神经网络也只对应于一个这样的数学函数——它实际上有数十亿项。
现在,让我们回头看看单个神经元。下图展示了一个具有两个输入 (代表坐标X和y)的神经元可以通过各种权重和常数(以及激活函数Ramp)计算出的一些示例。
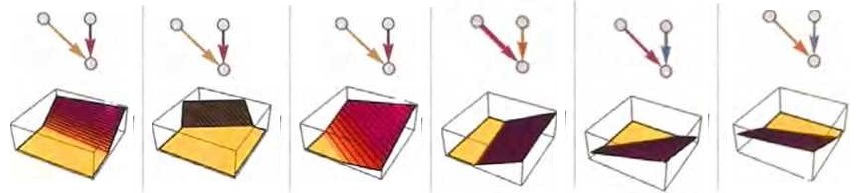
对于上面提到的更大的网络呢?它的计算结果如下所示。
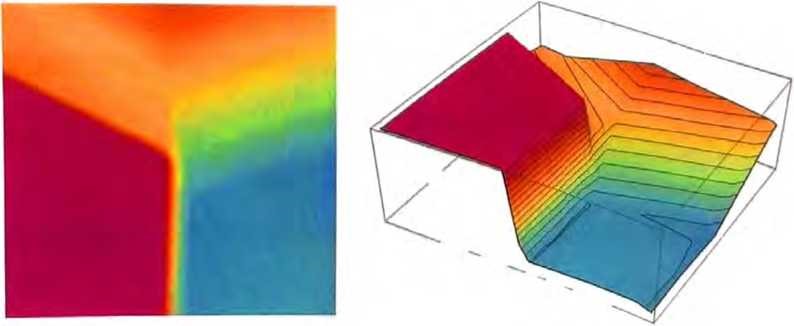
虽然不完全“正确”,但它接近上面展示的“最近点”函数。
再来看看其他的一些神经网络吧。在每种情况下,我们都使用机器学习来找到最佳的权重选择。这里展示了神经网络用这些权重计算出的结果。
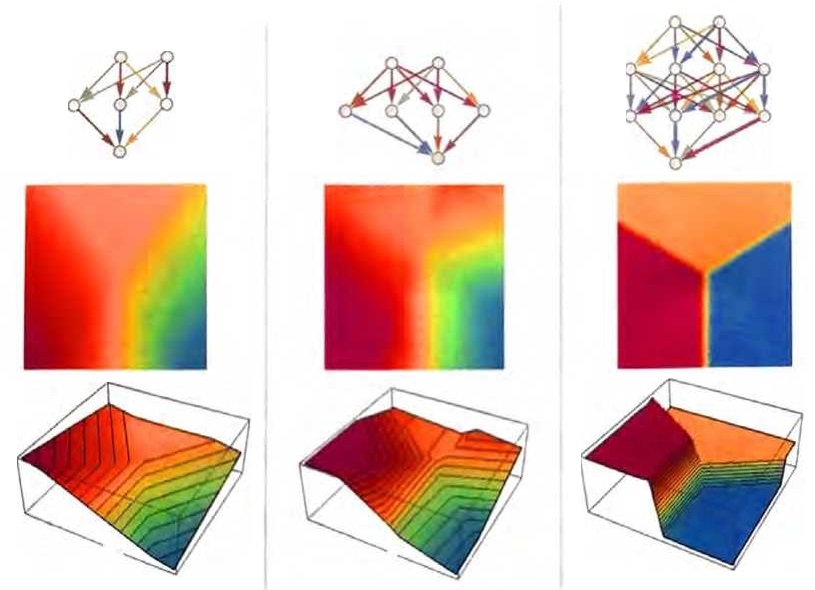
更大的神经网络通常能更好地逼近我们所求的函数。在“每个吸引子盆地的中心”,我们通常能确切地得到想要的答案。但在边界处,也就是神经网络“很难下定决心”的地方,情况可能会更加混乱。
在这个简单的数学式“识别任务”中,“正确答案”显而易见。但 在识别手写数字的问题上,答案就不那么明显了。如果有人把2写得像7一样怎么办?类似的问题非常常见。尽管如此,我们仍然可 以询问神经网络是如何区分数字的,下面给出了一个答案。

我们能“从数学上”解释网络是如何做出区分的吗?并不能。它只是在“做神经网络要做的事”。但是事实证明,这通常与我们人类 所做的区分相当吻合。
让我们更详细地讨论一个例子。假设我们有猫的图像和狗的图像, 以及一个经过训练、能区分它们的神经网络。以下是该神经网络可 能对某些图像所做的事情。

这里的“正确答案”更加不明显了。穿着猫咪衣服的狗怎么分?等等。无论输入什么,神经网络都会生成一个答案。结果表明,它的做法相当符合人类的思维方式。正如上面所说的,这并不是我们可以“根据第一性原则推导”出来的事实。这只是一些经验性的发 现,至少在某些领域是正确的。但这是神经网络有用的一个关键原因:它们以某种方式捕捉了 “类似人类”的做事方式。
找一张猫的图片看看,并问自己:“为什么这是一只猫?”你也许会说“我看到了它尖尖的耳朵”,等等。但是很难解释你是如何把这个图像识别为一只猫的。你的大脑就是不知怎么地想明白了。但是(至少目前还)没有办法去大脑“内部”看看它是如何想明白的。那么,对于(人工)神经网络呢?当你展示一张猫的图片时,很容易看到每个“神经元”的作用。不过,即使要对其进行基本的可视化,通常也非常困难。
在上面用于解决“最近点”问题的最终网络中,有17个神经元; 在用于识别手写数字的网络中,有2190个神经元;而在用于识别猫和狗的网络中,有60650个神经元。通常很难可视化出60 650 维的空间。但由于这是一个用于处理图像的网络,其中的许多神经元层被组织成了数组,就像它查看的像素数组一样。
下面以一个典型的猫的图像为例。

我们可以用一组衍生图像来表示第一层神经元的状态,其中的许多可以被轻松地解读为“不带背景的猫”或“猫的轮廓”。

到第10层,就很难解读这些是什么了。

但是总的来说,我们可以说神经网络正在“挑选出某些特征”(也许尖尖的耳朵是其中之一),并使用这些特征来确定图像的内容。 但是,这些特征能否用语言描述出来(比如“尖尖的耳朵”)呢? 大多数情况下不能。
我们的大脑是否使用了类似的特征呢?我们多半并不知道。但值得注意的是,一些神经网络(像上面展示的这个)的前几层似乎会挑 选出图像的某些方面(例如物体的边缘),而这些方面似乎与我们 知道的大脑中负责视觉处理的第一层所挑选出的相似。
假设我们想得到神经网络中的“猫识别理论”,可以说:“看,这个特定的网络可以做到这一点。”这会立即让我们对“问题的难度” 有一些了解(例如,可能需要多少个神经元或多少层)。但至少到 目前为止,我们没办法对网络正在做什么“给出语言描述”。也许 这是因为它确实是计算不可约的,除了明确跟踪每一步之外,没有 可以找出它做了什么的一般方法。也有可能只是因为我们还没有 “弄懂科学”,也没有发现能总结正在发生的事情的“自然法则”。
当使用生成语言时,我们会遇到类似的问题,而且目前尚不清楚是否有方法来“总结它所做的事情”。但是,语言的丰富性和细节(以及我们的使用经验)可能会让我们比图像处理取得更多进展。
机器学习和神经网络的训练
到目前为止,我们一直在讨论“已经知道”如何执行特定任务的神经网络。但神经网络之所以很有用(人脑中的神经网络大概也如此),原因不仅在于它可以执行各种任务,还在于它可以通过逐步 “根据样例训练”来学习执行这些任务。
当构建一个神经网络来区分猫和狗的图像时,我们不需要编写一个 程序来(比如)明确地找到胡须,只需要展示很多关于什么是猫和 什么是狗的样例,然后让神经网络从中“机器学习”如何区分它们 即可。
重点在于,已训练的神经网络能够对所展示的特定例子进行“泛 化”。正如我们之前看到的,神经网络不仅能识别猫图像的样例的 特定像素模式,还能基于我们眼中的某种“猫的典型特征”来区分 图像。 神经网络的训练究竟是如何起效的呢?本质上,我们一直在尝试找 到能使神经网络成功复现给定样例的权重。然后,我们依靠神经网 络在这些样例“之间”进行“合理”的“插值”(或“泛化”)。 让我们看一个比“最近点”问题更简单的问题,只试着让神经网络 学习如下函数。
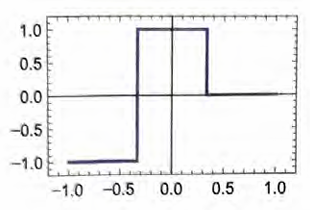
对于这个任务,我们需要只有一个输入和一个输出的神经网络。
但是,应该使用什么样的权重呢?对于每组可能的权重,神经网络都将计算出某个函数。例如,下面是它对于几组随机选择的权重计算出的函数。
可以清楚地看到,这些函数与我们想要的函数相去甚远。那么,如何才能找到能够复现函数的权重呢?
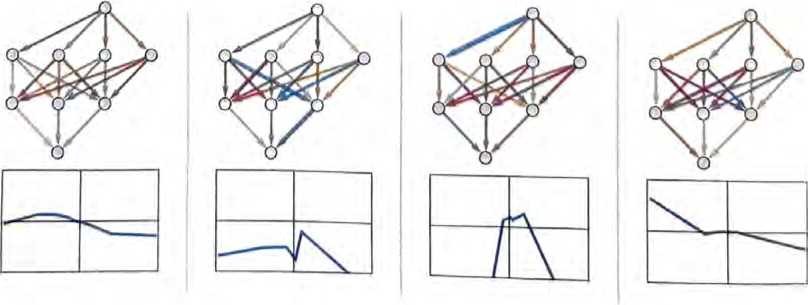
基本思想是提供大量的“输入—输出”样例以供“学习”,然后尝 试找到能够复现这些样例的权重。以下是逐渐增加样例后所得的 结果。 在该“训练”的每个阶段,都会逐步调整神经网络的权重,我们会 发现最终得到了一个能成功复现我们想要的函数的神经网络。应该 如何调整权重呢?基本思想是,在每个阶段看一下我们离想要的函 数“有多远”,然后朝更接近该函数的方向更新权重。
为了明白离目标“有多远”,我们计算“损失函数”(有时也称为 “成本函数”)。这里使用了一个简单的(L2)损失函数,就是我们 得到的值与真实值之间的差异的平方和。随着训练过程不断进行, 我们看到损失函数逐渐减小(遵循特定的“学习曲线”,不同任务的学习曲线不同),直到神经网络成功地复现(或者至少很好地近 似)我们想要的函数。
最后需要解释的关键是,如何调整权重以减小损失函数。正如我们 所说的,损失函数给出了我们得到的值和真实值之间的“距离”。 但是“我们得到的值”在每个阶段是由神经网络的当前版本和其中 的权重确定的。现在假设权重是变量,比如wi。我们想找出如何调 整这些变量的值,以最小化取决于它们的损失。
让我们对实践中使用的典型神经网络进行极大的简化,想象只有两 个权重w1和w2。然后,我们可能会有一个损失函数,它作为w1和w2的函数看起来如下所示。
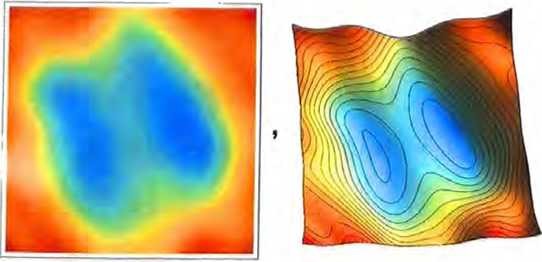
数值分析提供了各种技术来帮我们找到这种情况下的最小损失。一个典型的方法就是从之前的任意w1和w2开始,逐步沿着最陡的下降路径前进。
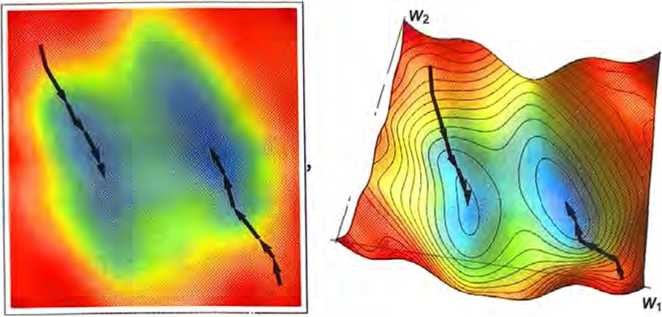
就像水从山上流下来一样,只能保证会到达表面上的某个局部最小 值(“一个山湖”),但不一定能到达最终的全局最小值。
似乎不太容易在“权重景观”中找到最陡的下降路径,但是微积分可以拯救我们。正如上面提到的,我们总是可以将神经网络视为计 算出一个数学函数一取决于其输入和权重。现在考虑对这些权重 进行微分。结果表明,微积分的链式法则实际上让我们解开了神经 网络中连续各层所做操作的谜团。结果是,我们可以一至少在某 些局部近似中一“反转”神经网络的操作,并逐步找到使与输出 相关的损失最小化的权重。
上图展示了,在仅有两个权重的情况下可能需要进行的最小化工作。但是事实证明,即使有更多的权重(ChatGPT使用了 1750亿个权重),也仍然可以进行最小化,至少可以在某种程度上进行近似。实际上,“深度学习”在2012年左右的重大突破与如下发现有关:与权重相对较少时相比,在涉及许多权重时,进行最小化(至 少近似)可能会更容易。
换句话说,有时候用神经网络解决复杂问题比解决简单问题更容易一这似乎有些违反直觉。大致原因在于,当有很多”权重变 量”时,髙维空间中有“很多不同的方向”可以引导我们到达最小值;而当变量较少时,很容易陷入局部最小值的“山湖”,无法找 到“出去的方向”。
值得指出的是,在典型情况下,有许多不同的权重集合可以使神经 网络具有几乎相同的性能。在实际的神经网络训练中,通常会做出 许多随机选择,导致产生一些“不同但等效”的解决方案,就像下面这些一样。

但是每个这样的“不同解决方案”都会有略微不同的行为。假如在 我们给出训练样例的区域之外进行“外插”(extrapolation),可能 会得到截然不同的结果。

哪一个是“正确”的呢?实际上没有办法确定。它们都“与观察到 的数据一致”。但它们都对应着“在已知框架外”进行“思考”的不 同的“固有方式”。只是有些方式对我们人类来说可能“更合理”。
神经网络训练的实践和学问
在过去的十年中,神经网络训练的艺术已经有了许多进展。是的, 它基本上是一门艺术。有时,尤其是回顾过去时,人们在训练中至 少可以看到一丝“科学解释”的影子了。但是在大多数情况下,这 些解释是通过试错发现的,并且添加了一些想法和技巧,逐渐针对 如何使用神经网络建立了一门重要的学问。
这门学问有几个关键部分。首先是针对特定的任务使用何种神经网 络架构的问题。然后是如何获取用于训练神经网络的数据的关键问 题。在越来越多的情况下,人们并不从头开始训练网络:一个新的网络可以直接包含另一个已经训练过的网络,或者至少可以使用该 网络为自己生成更多的训练样例。
有人可能会认为,每种特定的任务都需要不同的神经网络架构。 但事实上,即使对于看似完全不同的任务,同样的架构通常也 能够起作用。在某种程度上,这让人想起了通用计算(universal computation)的概念和我的计算等价性原理〈Principle of Computational Equivalence〉,但是,正如后面将讨论的那样,我 认为这更多地反映了我们通常试图让神经网络去完成的任务是“类人”任务,而神经网络可以捕捉相当普遍的“类人过程”。
在神经网络的早期发展阶段,人们倾向于认为应该“让神经网络做尽可能少的事”。例如,在将语音转换为文本时,人们认为应该先 分析语音的音频,再将其分解为音素,等等。但是后来发现,(至 少对于“类人任务”)最好的方法通常是尝试训练神经网络来“解 决端到端的问题”,让它自己“发现”必要的中间特征、编码等。
还有一种想法是,应该将复杂的独立组件引入神经网络,以便让它有效地“显式实现特定的算法思想”。但结果再次证明,这在大多 数情况下并不值得;相反,最好只处理非常简单的组件,并让它们 “自我组织”〔尽管通常是以我们无法理解的方式〕来实现(可能)等效的算法思想。
这并不意味着没有与神经网络相关的“结构化思想”。例如,至少 在处理图像的最初阶段,拥有局部连接的神经元二维数组似乎非常 有用。而且,拥有专注于“在序列数据中‘回头看’”的连接模式 在处理人类语言方面,例如在ChatGPT中,似乎很有用(后面我们将看到)。
神经网络的一个重要特征是,它们说到底只是在处理数据一和计算机一样。目前的神经网络及其训练方法具体处理的是由数值组成 的数组,但在处理过程中,这些数组可以完全重新排列和重塑。例如,前面用于识别数字的网络从一个二维的“类图像”数组开始, 迅速“增厚”为许多通道,但然后会“浓缩”成一个一维数组,最 终包含的元素代表可能输出的不同数字。
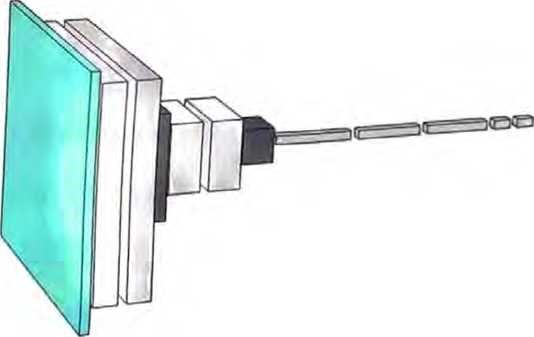
但是,如何确定特定的任务需要多大的神经网络呢?这有点像一门 艺术。在某种程度上,关键是要知道“任务有多难”。但是类人任务的难度通常很难估计。是的,可能有一种系统化的方法可以通过 计算机来非常“机械”地完成任务,但是很难知道是否有一些技巧 或捷径有助于更轻松地以“类人水平”完成任务。可能需要枚举一 棵巨大的对策树才能“机械”地玩某个游戏,但也可能有一种更简 单的(“启发式”)方法来实现“类人的游戏水平”。
当处理微小的神经网络和简单任务时,有时可以明确地看到“无法从这里到达那里”。例如,下面是在上一节任务中的几个小神经网 络能够得到的最佳结果。
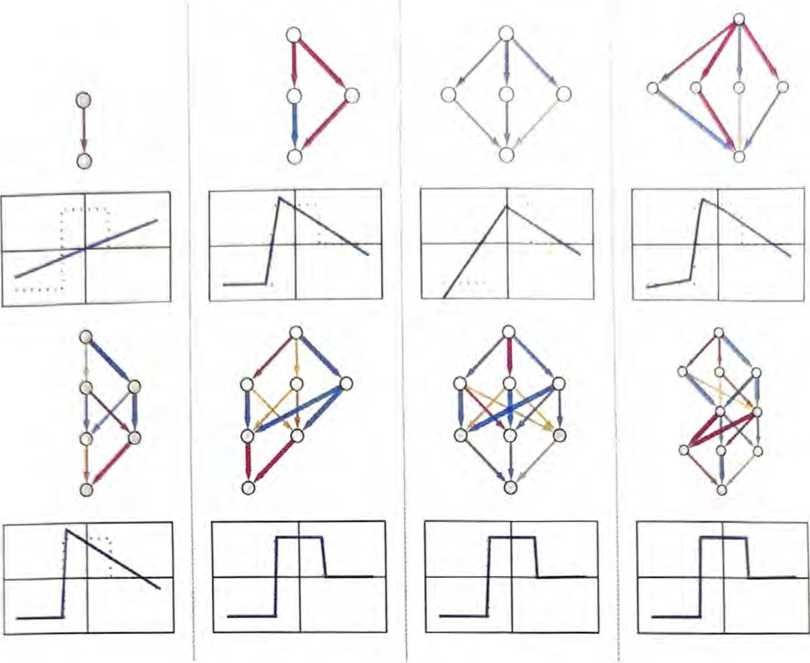
我们看到的是,如果神经网络太小,它就无法复现我们想要的函 数。但是只要超过某个大小,它就没有问题了 一一前提是至少训 练足够长的时间,提供足够的样例。顺便说一句,这些图片说明了 神经网络学问中的一点:如果中间有一个“挤压”〈squeeze〉,迫 使一切都通过中间较少的神经元,那么通常可以使用较小的网络。 [值得一提的是,“无中间层”(或所谓的“感知机”)网络只能学习 基本线性函数,但是只要有一个中间层(至少有足够的神经元),原则上就始终可以任意好地逼近任何函数,尽管为了使其可行地训 练,通常会做某种规范化或正则化。]
好吧,假设我们已经确定了一种特定的神经网络架构。现在的问题是如何获取用于训练网络的数据。神经网络(及广义的机器学习)的许多实际挑战集中在获取或准备必要的训练数据上。在许多情况 (“监督学习”)下,需要获取明确的输入样例和期望的输出。例如, 我们可能希望根据图像中的内容或其他属性添加标签,而浏览图像 并添加标签通常需要耗费大量精力。不过很多时候,可以借助已 有的内容或者将其用作所需内容的替代。例如,可以使用互联网 上提供的alt标签。还有可能在不同的领域中使用为视频创建的隐 藏式字幕。对于语言翻译训练,可以使用不同语言的平行网页或平行文档。
为特定的任务训练神经网络需要多少数据?根据第一性原则很难估 计。使用“迁移学习”可以将已经在另一个神经网络中学习到的重 要特征列表“迁移过来”,从而显著降低对数据规模的要求。但是, 神经网络通常需要“看到很多样例”才能训练好。至少对于某些任 务而言,神经网络学问中很重要的一点是,样例的重复可能超乎想 象。事实上,不断地向神经网络展示所有的样例是一种标准策略。 在每个“训练轮次”〈training round或epoch〉中,神经网络都会 处于至少稍微不同的状态,而且向它“提醒”某个特定的样例对于它“记忆该样例”是有用的。(是的,这或许类似于重复在人类记忆中的有用性。)
然而,仅仅不断重复相同的样例并不够,还需要向神经网络展示样 例的变化。神经网络学问的一个特点是,这些“数据增强”的变 化并不一定要很复杂才有用。只需使用基本的图像处理方法稍微修改图像,即可使其在神经网络训练中基本上“像新的一样好”。与之类似,当人们在训练自动驾驶汽车时用完了实际的视频等数据, 可以继续在模拟的游戏环境中获取数据,而不需要真实场景的所 有细节。
那么ChatGPT呢?它有一个很好的特点,就是可以进行“无监督 学习”,这样更容易获取训练样例。回想一下,ChatGPT的基本任 务是弄清楚如何续写一段给定的文本。因此,要获得“训练样例”, 要做的就是取一段文本,并将结尾遮盖起来,然后将其用作“训练 的输入”,而“输出”则是未被遮盖的完整文本。我们稍后会更详 细地讨论这个问题,这里的重点是一(与学习图像内容不同)不 需要“明确的标签”,ChatGPT实际上可以直接从它得到的任何文本样例中学习。
神经网络的实际学习过程是怎样的呢?归根结底,核心在于确定哪 些权重能够最好地捕捉给定的训练样例。有各种各样的详细选择 和“超参数设置”(之所以这么叫,是因为权重也称为“参数”), 可以用来调整如何进行学习。有不同的损失函数可以选择,如平方和、绝对值和,等等。有不同的损失最小化方法,如每一步在权重 空间中移动多长的距离,等等。然后还有一些问题,比如“批量” (batch)展示多少个样例来获得要最小化的损失的连续估计。是的,我们可以(像在语言中所做的一样)应用机器学习来自动化机器学习,并自动设置超参数等。
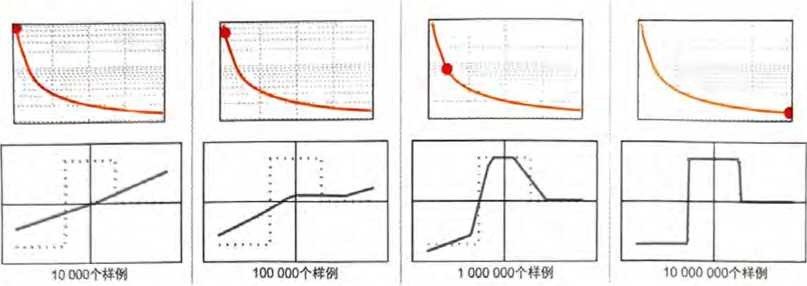
最终,整个训练过程可以通过损失的减小趋势来描述(就像这个经 过小型训练的Wolfram语言进度监视器一样)。
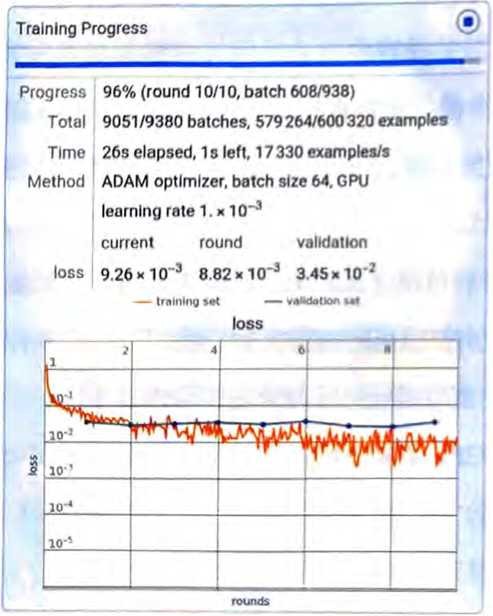
损失通常会在一段时间内逐渐减小,但最终会趋于某个恒定值。如 果该值足够小,可以认为训练是成功的;否则可能暗示着需要尝试 更改网络的架构。
能确定“学习曲线”要多久才能趋于平缓吗?似乎也存在—种取决 于神经网络大小和数据量的近似幂律缩放关系。但总的结论是,训练神经网络很难,并且需要大量的计算工作。实际上,绝大部分工 作是在处理数的数组,这正是GPU擅长的一’这也是为什么神经 网络训练通常受限于可用的GPU数量。
未来,是否会有更好的方法来训练神经网络或者完成神经网络的任 务呢?我认为答案几乎是肯定的。神经网络的基本思想是利用大量 简单(本质上相同)的组件来创建一个灵活的“计算结构”,并使 其能够逐步通过学习样例得到改进。在当前的神经网络中,基本上是利用微积分的思想(应用于实数)来进行这种逐步的改进。但越 来越清楚的是,重点并不是拥有高精度数值,即使使用当前的方法,8位或更少的数也可能已经足够了。
对于像元胞自动机这样大体是在许多单独的位上进行并行操作的 计算系统,虽然我们一直不明白如何进行这种增量改进,但没有 理由认为这不可能实现。实际上,就像“2012年的深度学习突 破”一样,这种增量改进在复杂情况下可能会比在简单情况下更容易实现。
神经网络(或许有点像大脑)被设置为具有一个基本固定的神经 元网络,能改进的是它们之间连接的强度(“权重”)。(或许在年轻的大脑中,还可以产生大量全新的连接。)虽然这对生物学来说 可能是一种方便的设置,但并不清楚它是否是实现我们所需功能 的最佳方式。涉及渐进式网络重写的东西(可能类似于我们的物理项目)可能最终会做得更好。
但即使仅在现有神经网络的框架内,也仍然存在一个关键限制:神 经网络的训练目前基本上是顺序进行的,每批样例的影响都会被反 向传播以更新权重。事实上,就目前的计算机硬件而言,即使考虑 到神经网络的大部分在训练期间的大部分时间里也是“空 闲”的,一次只有一个部分被更新。从某种意义上说,这是因为当 前的计算机往往具有独立于CPU (或GPU)的内存。但大脑中的 情况可能不同一一每个“记忆元素”(即神经元)也是一个潜在的活跃的计算元素。如果我们能够这样设置未来的计算机硬件,就可 能会更高效地进行训练。
“足够大的神经网络当然无所不能!”
ChatGPT的能力令人印象深刻,以至于人们可能会想象,如果能够 在此基础上继续努力,训练出越来越大的神经网络,那么它们最终 将“无所不能”。对于那些容易被人类思维理解的事物,这确实很 可能是成立的。但我们从科学在过去几百年间的发展中得出的教训 是,有些事物虽然可以通过形式化的过程来弄清楚,但并不容易立 即为人类思维所理解。
非平凡的数学就是一个很好的例子,但实际而言,一般的例子是计 算。最终的问题是计算不可约性。有些计算虽然可能需要很多步才 能完成,但实际上可以“简化”为相当直接的东西。但计算不可约 性的发现意味着这并不总是有效的。对于一些过程〈可能像下面的例子一样〉,无论如何都必须回溯每个计算步骤才能弄清楚发生了 什么。

我们通常用大脑做的那类事情,大概是为了避免计算不可约性而特 意选择的。在大脑中进行数学运算需要特殊的努力。而且在实践 中,仅凭大脑几乎无法“想透”任何非平凡程序的操作步骤。
当然,我们可以用计算机来做这些。有了计算机,就可以轻松地完 成耗时很长、计算不可约的任务。关键是,完成这些任务一般来说 没有捷径可走。
是的,我们可以记住在某个特定计算系统中发生的事情的许多具体 例子,也许甚至可以看到一些(计算可约的)模式,使我们能够做 一些泛化。但关键是,计算不可约性意味着我们永远不能保证意外 不会发生一一只有通过明确的计算,才能知道在任何特定的情况下 会实际发生什么。
说到底,可学习性和计算不可约性之间存在根本的矛盾。学习实际 上涉及通过利用规律来压缩数据,但计算不可约性意味着最终对可 能存在的规律有一个限制。
在实践中,人们可以想象将(像元胞自动机或图灵机这样的)小 型计算设备构建到可训练的神经网络系统中。实际上,这样的设 备可以成为神经网络的好“工具”,就像Wolfram|Alpha可以成为ChatGPT的好工具一样。但是计算不可约性意味着人们不能指望 “进入”这些设备并让它们学习。
换句话说,能力和可训练性之间存在着一个终极权衡:你越想让一个系统“真正利用”其计算能力,它就越会表现出计算不可约性,从而越不容易被训练;而它在本质上越易于训练,就越不能进行复 杂的计算。
(对于当前的ChatGPT,情况实际上要极端得多,因为用于生成每 个输出标记的神经网络都是纯“前馈”网络、没有循环,因此无法 使用非平凡“控制流”进行任何计算。)
当然,你可能会问,能够进行不可约计算是否真的很重要。实际 上,在人类历史的大部分时间里,这并不是特别重要。但我们的现 代技术世界是建立在工程学的基础上的,而工程学利用了数学计算,并且越来越多地利用了更一般的计算。看看自然界,会发现它充满了不可约计算^我们正在慢慢地理解如何模拟和利用它们来 达到我们的技术目的。
神经网络确实可以注意到自然界中我们通过“无辅助的人类思维” 也能轻易注意到的规律。但是,如果我们想解决数学或计算科学 领域的问题,神经网络将无法完成任务,除非它能有效地使用一个 “普通”的计算系统作为“工具”。
但是,这一切可能会带来一些潜在的困惑。过去,我们认为计算机 完成很多任务(包括写文章)在“本质上太难了”。现在我们看到像ChatGPT这样的系统能够完成这些任务,会倾向于突然认为计 算机一定变得更加强大了,特别是在它们已经基本能够完成的事情 (比如逐步计算元胞自动机等计算系统的行为)上实现了超越。
但这并不是正确的结论。计算不可约过程仍然是计算不可约的,对 于计算机来说仍然很困难,即使计算机可以轻松计算其中的每一 步。我们应该得出的结论是,(像写文章这样)人类可以做到但认为计算机无法做到的任务,在某种意义上计算起来实际上比我们想象的更容易。
换句话说,神经网络能够在写文章的任务中获得成功的原因是,写 文章实际上是一个“计算深度较浅”的问题,比我们想象的简单。 从某种意义上讲,这使我们距离对于人类如何处理类似于写文章的事情(处理语言)“拥有一种理论”更近了一步。
如果有一个足够大的神经网络,那么你可能能够做到人类可以轻易 做到的任何事情。但是你无法捕捉自然界一般而言可以做到的事 情,或者我们用自然界塑造的工具可以做到的事情。而正是这些工 具的使用,无论是实用性的还是概念性的,近几个世纪以来使我们 超越了“纯粹的无辅助的人类思维”的界限,为人类获取了物理宇 宙和计算宇宙之外的很多东西。
嵌入”的概念
神经网络,至少以目前的设置来说,基本上是基于数的。因此,如 果要用它来处理像文本这样的东西,我们需要一种用数表示文本的 方法。当然,我们可以(本质上和ChatGPT 一样)从为字典中的 每个词分配一个数开始。但有一个重要的思想一也是ChatGPT的中心思想一更胜一筹。这就是“嵌入”(embedding)的思想。 可以将嵌入视为一种尝试通过数的数组来表示某些东西“本质”的 方法,其特性是“相近的事物”由相近的数表示。
例如,我们可以将词嵌入视为试图在一种“意义空间”中布局词, 其中“在意义上相近”的词会出现在相近的位置。实际使用的嵌入(例如在ChatGPT中)往往涉及大量数字列表。但如果将其投影到二维平面上,则可以展示嵌入对词的布局方式。

可以看到,这确实非常成功地捕捉了我们典型的日常印象。但是如 何才能构建这样的嵌入呢?大致的想法是查看大量的文本〔这里查看了来自互联网的50亿个词〕,然后看看各个词出现的“环境”有 多“相似”。例如,alligator(短吻鳄)和crocodile(鳄鱼)在相似 的句子中经常几乎可以互换,这意味着它们将在嵌入中被放在相近 的位置。但是,turnip(芜菁)和eagle(鹰)一般不会出现在相似的句子中,因此将在嵌入中相距很远。
如何使用神经网络实际实现这样的机制呢?让我们从讨论图像的嵌 入而非词嵌入开始。我们希望找到一种以数字列表来表征图像的方 法,以便为“我们认为相似的图像”分配相似的数字列表。
如何判断我们是否应该“认为图像相似”呢?对于手写数字图像, 如果两个图像是同一个数字,我们就可能会认为它们是相似的。前 面,我们讨论了一个被训练用于识别手写数字的神经网络。可以将 这个神经网络看作被设置成在最终输出中将图像放入10个不同的 箱(bin)中,每个箱对应一个数字。
如果在神经网络做出“这是4”的最终决策之前“拦截”其内部进 程,会发生什么呢?我们可能会期望,神经网络内部有一些数值, 将图像表征为“大部分类似于4但有点类似于2”。想法是获取这 些数值并将其作为嵌入中的元素使用。
这里的关键概念是,我们不直接尝试表征“哪个图像接近哪个图 像”,而是考虑一个定义良好、可以获取明确的训练数据的任务 (这里是数字识别),然后利用如下事实:在完成这个任务时,神经 网络隐含地必须做出相当于“接近度决策”的决策。因此,我们不 需要明确地谈论“图像的接近度”,而是只谈论图像代表什么数字 的具体问题,然后“让神经网络”隐含地确定这对于“图像的接近度”意味着什么。
对于数字识别网络来说,这是如何具体操作的呢?我们可以将该网 络想象成由11个连续的层组成,并做如下简化(将激活函数显示为单独的层)。
在开始,我们将实际图像输入第一层,这些图像由其像素值的二维数组表示。在最后,我们(从最后一层)得到一个包含10个值的数组,可以认为这些值表示网络对图像与数字0到9的对应关系的 确定程度。
输入图像4,最后一层中神经元的值为
{1.42071×10-22, 7.69857×10-14,1.9653×10-16, 5.55229×10-21, 1., 8.33841×10-14, 6.89742×10-17,6.52282×10-19, 6.51465×10-12, 1.97509×10-14)
换句话说,神经网络现在“非常确定”这个图像是一个4——为了得到输出的4,我们只需要找出具有最大值的神经元的位置。
如果我们再往前看一步呢?网络中的最后一个操作是所谓的softmax,它试图“强制推出确定性”。在此之前,神经元的值是
{-26.134, -6.02347, -11.994, -22.4684, 24.1717, -5.94363, -13.0411, -17.7021, -1.58528, -7.38389}
代表数字4的神经元仍然具有最大的数值,但是其他神经元的值中 也有信息。我们可以期望这个数字列表在某种程度上能用来表征图 像的“本质”,从而提供可以用作嵌入的东西。例如,这里的每个 4都具有略微不同的“签名”(或“特征嵌入”),与8完全不同。

这里,我们基本上是用10个数来描述图像的。但使用更多的数通 常更好。例如,在我们的数字识别网络中,可以通过接入前一层来 获取一个包含500个数的数组。这可能是一个可以用作“图像嵌 入”的合理数组。
如果想要对手写数字的“图像空间”进行明确的可视化,需要将我 们得到的500维向量投影到(例如)三维空间中来有效地“降维”。

我们刚刚谈论了为图像创建特征(并嵌入)的方法,它的基础实际 上是通过(根据我们的训练集〉确定一些图像是否对应于同一个手 写数字来识别它们的相似性。如果我们有一个训练集,可以识别每 个图像属于5000种常见物体(如猫、狗、椅子……)中的哪一种, 就可以做更多这样的事情。这样,就能以我们对常见物体的识别 为“锚点”创建一个图像嵌入,然后根据神经网络的行为“围绕它 进行泛化”。关键是,这种行为只要与我们人类感知和解读图像的 方式一致,就将最终成为一种“我们认为正确”且在实践中对执行 “类人判断”的任务有用的嵌入。
那么如采用相同的方法来找到对词的嵌入呢?关键在于,要从一个我们可以轻松训练的任务开始。一个这样的标准任务是词预测。 想象一下,给定问题“the_cat”。基于一个大型文本语料库,比如互联网上的文本内容,可能用来“填空”的各个词的概率分别是 多少?或者给定“_black_”,不同的“两侧词”的概率分别是多少?
如何为神经网络设置这个问题呢?最终,我们必须用数来表述一 切。一种方法是为英语中约50000个常用词分别分配一个唯一的数。例如,分配给the的可能是914,分配给cat的的可能是3542。(这些是GPT-2实际使用的数。)因此,对于“the_cat”的问 题,我们的输入可能是丨914, 3542丨。输出应该是什么样的呢? 应该是一个大约包含500000个数的列表,有效地给出了每个可能“填入”的词的概率。为了找到嵌入,我们再次在神经网络“得到 结论”之前“拦截”它的“内部”进程,然后获取此时的数字列 表,可以认为这是“每个词的表征”。
这些表征是什么样子的呢?在过去10年里,已经出现了一系列不 同的系统(word2vec、G1oVe、BERT、GPT……),每个系统都基 于一种不同的神经网络方法。但最终,所有这些系统都是通过有几 百到几千个数的列表对词进行表征的。
这些“嵌入向量”在其原始形式下是几乎无信息的。例如,下面是 为三个特定的词生成的原始嵌入向量。

如果测量这些向量之间的距离,就可以找到词之间的“相似度”。 我们稍后将更详细地讨论这种嵌入的“认知”意义可能是什么,而 现在的要点是,我们有一种有用的方法能将词转化为“对神经网络 友好”的数字集合。
实际上,比起用一系列数对词进行表征,我们还可以做得更好一 可以对词序列甚至整个文本块进行这样的表征。ChatGPT内部就是这样进行处理的。它会获取到目前为止的所有文本,并生成一个嵌 入向量来表示它。然后,它的目标就是找到下一个可能出现的各个 词的概率。它会将答案表示为一个数字列表,这些数基本上给出了 大约50000个可能出现的词的概率。
[严格来说,ChatGPT并不处理词,而是处理“标记”(token)——这是一种方便的语言单位,既可以是整个词,也可以只是像pre、ing或ized这样的片段。使用标记使ChatGPT更容易处理罕见词、 复合词和非英语词,并且会发明新单词(不论结果好坏)。]
ChatGPT的内部原理
我们终于准备好讨论ChatGPT的内部原理了。从根本上说,ChatGPT是一个庞大的神经网络——GPT-3拥有1750亿个权重。 它在许多方面非常像我们讨论过的其他神经网络,只不过是一个 特别为处理语言而设置的神经网络。它最显著的特点是一个称为Transformer的神经网络架构。
在前面讨论的神经网络中,任何给定层的每个神经元基本上都与 上一层的每个神经元相连(起码有一些权重)。但是,如果处理的 数据具有特定的已知结构,则这种全连接网络就(可能)大材小用 了。因此,以图像处理的早期阶段为例,通常使用所谓的卷积神经 网络(convolutional neural net或convnet),其中的神经元被有效 地布局在类似于图像像素的网格上,并且仅与在网格上相邻的神经元相连。
Transformer的思想是,为组成一段文本的标记序列做与此相似的 事情。但是,Transformer不是仅仅定义了序列中可以连接的固定 区域,而是引入了“注意力”的概念一即更多地“关注”序列 的某些部分,而不是其他部分。也许在将来的某一天,可以启动一个通用神经网络并通过训练来完成所有的定制工作。但至少目前来看,在实践中将事物“模块化”似乎是至关重要的——就像Transformer所做的那样,也可能是我们的大脑所做的那样。
ChatGPT(或者说它基于的GPT-3网络)到底是在做什么呢?它 的总体目标是,根据所接受的训练(查看来自互联网的数十亿页文 本,等等〉,以“合理”的方式续写文本。所以在任意给定时刻, 它都有一定量的文本,而目标是为要添加的下一个标记做出适当的 选择。
它的操作分为三个基本阶段。第一阶段,它获取与目前的文本相对 应的标记序列,并找到表示这些标记的一个嵌入(即由数组成的数 组兑第二阶段,它以“标准的神经网络的方式”对此嵌入进行操 作,值“像涟漪一样依次通过”网络中的各层,从而产生一个新的嵌入(即一个新的数组第三阶段,它获取此数组的最后一部分, 并据此生成包含约50000个值的数组,这些值就成了各个可能的 下一个标记的概率。(没错,使用的标记数量恰好与英语常用词的 数量相当,尽管其中只有约3000个标记是完整的词,其余的则是片段。)
关键是,这条流水线的每个部分都由一个神经网络实现,其权重是 通过对神经网络进行端到端的训练确定的。换句话说,除了整体架构,实际上没有任何细节是有“明确设计”的,一切都是从训练数据中“学习”来的。
然而,架构设置中存在很多细节,反映了各种经验和神经网络的学 问。尽管会变得很复杂,但我认为谈论一些细节是有用的,至少有 助于了解构建需要做多少工作。
首先是嵌入模块。以下是GPT-2的Wolfram语言示意图。
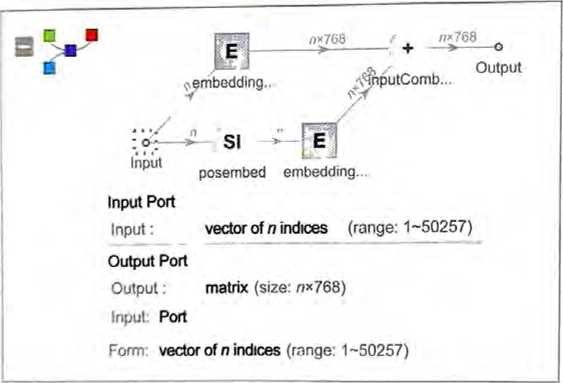
输入是一个包含n个〈由整数1到大约50 000表示的〉标记的向 量。每个标记都(通过一个单层神经网络)被转换为一个嵌入向量 (在中长度为768,在ChatGPT-2的GPT-3中长度为12288 同时,还有一条“二级路径”,它接收标记的(整数〉位置序列, 并根据这些整数创建另一个嵌入向量。最后,将标记值和标记位置 的嵌入向量相加,产生嵌入糢块的最终嵌入向量序列。
为什么只是将标记值和标记位置的嵌入向量相加呢?我不认为有什 么特别的科学依据。只是因为尝试了各种不同的方法,而这种方法 似乎行得通。此外,神经网络的学问告诉我们,(在某种意义上) 只要我们的设置“大致正确”,通常就可以通过足够的训练来确定 细节,而不需要真正“在工程层面上理解”神经网络是如何配置自己的。
嵌入模块对字符串“hello hello hello hello hello hello hello hello hello hello bye bye bye bye bye bye bye bye bye)所做的操作如下所示。
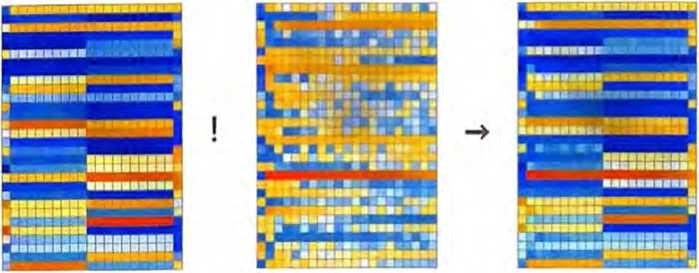
(在上图的第一个数组中)每个标记的嵌入向量元素都在图中纵向 显示,而从左往右看,首先是一系列hello嵌入,然后是一系列bye嵌入。上面的第二个数组是位置嵌入,它看起来有些随机的结 构只是(这里是在中〉“碰巧学到”的。
在嵌入模块之后,就是Transformer的“主要事件”了 :一系列所 谓的“注意力块”〈GPT-2有12个,ChatGPT的GPT-3有96个〉。
整个过程非常复杂,让人想起难以理解的大型工程系统或者生物系 统。以下是(GPT-2中)单个“注意力块”的示意图。
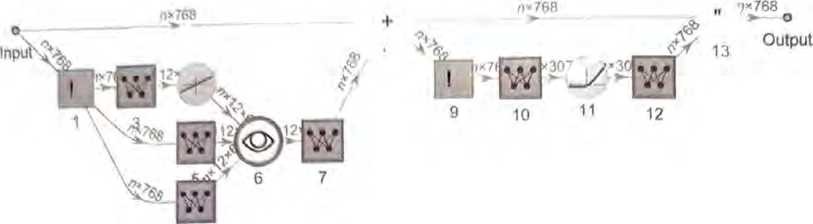
在每个这样的注意力块中,都有―组“注意力头”〈GPT-2有12个,ChatGPT的GPT-3有96个〉——每个都独立地在嵌入向量的 不同值块上进行操作。(我们不知道为什么最好将嵌入向量分成不 同的部分,也不知道不同的部分“意味”着什么。这只是那些“被 发现奏效”的事情之一。)
注意力头是做什么的呢?它们基本上是一种在标记序列(即目前已 经生成的文本〉中进行“回顾”的方式,能以一种有用的形式“打 包过去的内容”,以便找到下一个标记。在“概率从何而来”一节 中,我们介绍了使用二元词的概率来根据上一个词选择下一个词。Transformer中的“注意力”机制所做的是允许“关注”更早的词, 因此可能捕捉到(例如〉动词可以如何被联系到出现在句子中很多 词之前的名词。
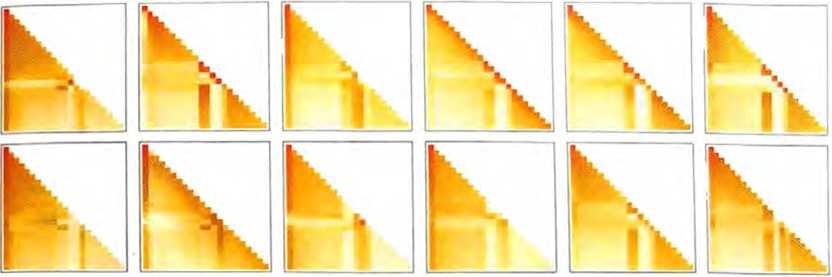
更详细地说,注意力头所做的是,使用一定的权重重新加权组合 与不同标记相关联的嵌入向量中的块。例如,对于上面的“hello,bye”字符串,(GPT-2中)第一个注意力块中的12个注意力头具有以下(“回顾到标记序列开头”的)“权重重组”模式。
经过注意力头的处理,得到的“重新加权的嵌入向量”(在GPT-2中长度为768,在GPT-3中长度为12288)将被传递通过标准的“全连接”神经网络层。虽然很难掌握这一层的作用, 但是可以看看它(这里是在GPT-2中)使用的768 X 768权重矩阵。

(对上图进行)4 X 64的滑动平均处理,一些(随机游走式的)结构开始显现。
是什么决定了这种结构?说到底,可能是对人类语言特征的一些 “神经网络编码”。但是到目前为止,这些特征到底是什么仍是未知 的。实际上,我们正在“打开ChatGPT(或者至少是的GPT-2)大脑”,并发现里面很复杂、难以理解——尽管它最终产生了可识别 的人类语言。
经过一个注意力块后,我们得到了一个新的嵌入向量,然后让它 依次通过其他的注意力块(GPT-2中共有12个,GPT-3中共有96个)。每个注意力块都有自己特定的“注意力”模式和“全连接” 权重。这里是GPT-2对于“hello,bye”输入的注意力权重序列,用于第一个注意力头。
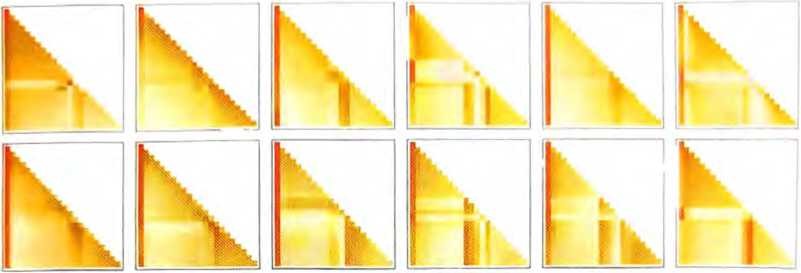
全连接层的(移动平均)“矩阵”如下所示。
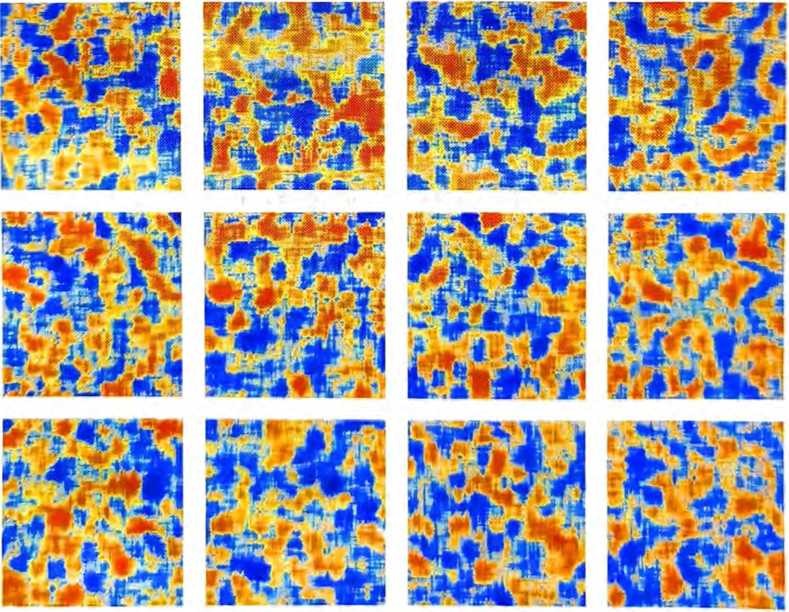
奇怪的是,尽管不同注意力块中的“权重矩阵”看起来非常相似, 徂权重大小的分布可能会有所不同〈而且并不总是服从髙斯分布)。
在经过所有这些注意力块后,Transformer的实际效果是什么?本质上,它将标记序列的原始嵌入集合转换为最终集合。ChatGPT的特定工作方式是,选择此集合中的最后一个嵌入,并对其进行“解 码”,以生成应该出现的下一个标记的概率列表。
以上就是对ChatGPT内部原理的概述。它虽然(由于许多难免有 些随意的“工程选择”)可能看起来很复杂,但实际上涉及的最终 元素非常简单。因为我们最终处理的只是由“人工神经元”构成的 神经网络,而每个神经元执行的只是将一组数值输入与一定的权重 相结合的简单操作。
ChatGPT的原始输入是一个由数组成的数组(到目前为止标记的嵌 入向量)。当ChatGPT“运行”以产生新标记时,这些数就会“依次通过”神经网络的各层,而每个神经元都会“做好本职工作”并将结果传递给下一层的神经元。没有循环和“回顾”。—切都是在 网络中“向前馈送”的。
这是与典型的计算系统(如图灵机)完全不同的设置——在这里, 结果不会被同一个计算元素“反复处理”。至少在生成给定的输出 标记时,每个计算元素(神经元)仅使用了一次。
但是在某种意义上,即使在ChatGPT中,仍然存在一个重复使用 计算元素的“外部循环”。因为当ChatGPT要生成一个新的标记时,它总是“读取”〈即获取为输入〉之前的整个标记序列,包括ChatGPT自己先前“写入”的标记。我们可以认为这种设置意味着 确实,至少在其最外层,包含一个“反馈循环”,尽管其 中的每次迭代都明确显示为它所生成文本中的一个标记。
让我们回到ChatGPT的核心:神经网络被反复用于生成每个标记。 在某种程度上,它非常简单:就是完全相同的人工神经元的一个集 合。网络的某些部分仅由(“全连接”的)神经元层组成,其中给 定层的每个神经元都与上一层的每个神经元(以某种权重〉相连。 但是由于特别的架构,ChatGPT的一些部分具有其他的结构,其中仅连接不同层的特定神经元。(当然,仍然可以说 “所有神经元都连接在一起”,但有些连接的权重为零。)
此外,ChatGPT中神经网络的有些方面并不能被顺理成章地认为 只由“同质”层组成。例如,(正如本节中单个“注意力块”的示 意图所示)在注意力块内有一些对传入的数据“制作多个副本”的 地方,每个副本都会通过不同的“处理路径”,可能涉及不同数量的层,然后才被重新组合。虽然这可能简便地表示了正在发生的事 情,但至少原则上总是可以将事实考虑为“密集填充”各层,只是 有一些权重为零。
看一下ChatGPT最长的路径,会发现大约有400个(核心)层——在某种程度上看来并不是很多。但是它们包括数百万个神经 元,总共有1750亿个连接,因此有1750亿个权重。需要认识到的 一件事是,ChatGPT每生成一个新的标记,都必须进行一次包括所有这些权重在内的计算。在实现上,这些计算可以“按层”组织成 高度并行的数组操作,方便地在上完成。但是对于每个产生 的标记,仍然需要进行1750亿次计算(并在最后进行一些额外的 计算)——因此,不难理解使用ChatGPT生成一段长文本需要一些时间。
值得注意的是,所有这些操作——尽管各自都很简单——可以一 起出色地完成生成文本的“类人”工作。必须再次强调,(至少就 我们目前所知〕没有“理论上的终极原因”可以解释为什么类似于 这样的东西能够起作用。事实上,正如我们将讨论的那样,我认为 必须将其视为一项(可能非常惊人的)科学发现:在像ChatGPT这样的神经网络中,能以某种方式捕捉到人类大脑在生成语言时所做事情的本质。
ChatGPT的训练
我们已经概述了ChatGPT在设置后的工作方式。但是它是如何设 置的呢?那1750亿个神经元的权重是如何确定的呢?基本上,这 是基于包含人类所写文本的巨型语料库(来自互联网、书籍等〉, 通过大规模训练得出的结果。正如我们所说,即使有所有这些训练 数据,也不能肯定神经网络能够成功地产生“类人”文本。似乎需 要细致的工程设计才能实现这一点。但是,ChatGPT带来的一大惊 喜和发现是,它完全可以做到。实际上,“只有1750亿个权重”的 神经网络就可以构建出人类所写文本的一个“合理模型”。
现代社会中,人类写的很多文本以数字(digital)形式存在。公共 互联网上至少有数十亿个包含人类所写文本的网页,总词数可能 达到万亿级别。如果包括非公开的网页,词数可能会增加至少100 倍。到目前为止,已经有超过500万本电子书可供阅读(全球发行的图书品种总数为1亿左右〉,提供了另外约1000亿个词的文本。 这还不包括视频中的口述文本等。(就个人而言,我一生中发表的 文字总量不到300万个词,在过去30年中写下了约1500万个词的 电子邮件,总共敲了大约5000万个词一而且仅在过去几年的直播 中,我就说了超过1000万个词。是的,我会从中训练一个机器人。)
但是,有了所有这些数据,要如何训练神经网络呢?基本过程与 上面讨论的简单示例非常相似:先提供一批样例,然后调整网络 中的权重,以最小化网络在这些样例上的误差(“损失”)。根据误 差“反向传播”的主要问题在于,每次执行此操作时,网络中的每 个权重通常都至少会发生微小的变化,而且有很多权重需要处理。 〈实际的“反向传播”通常只比前向传播难—点儿一一相差一个很 小的常数系数。) 使用现代硬件,可以轻松地从成千上万个样例中并行计算出 结果。但是,当涉及实际更新神经网络中的权重时,当前的方法基 本上会要求逐批进行。(是的,这可能是结合了计算元素和记忆元 素的真实大脑至少在现阶段具有架构优势的地方。) 即使在学习数值函数这样看似简单的案例中,我们通常也需要使用 数百万个样例才能成功地训练网络,至少对于从头开始训练来说是 这样的。那么需要多少样例才能训练出“类人语言”模型呢?似乎 无法通过任何基本的“理论”方法知道。但在实践中,ChatGPT成功地在包含几百亿个词的文本上完成了训练。
虽然有些文本被输入了多次,有些只输入了一次,但ChatGPT从 它看到的文本中“得到了所需的信息”。考虑到有这么多文本需要学习,它需要多大的网络才能“学得好”呢?目前,我们还没有基 本的理论方法来回答这个问题。最终,就像下面将进一步讨论的那样,对于人类语言和人类通常用它说什么,可能有某种“总体算法 内容”。而下一个问题是:神经网络在基于该算法内容实现模型时 会有多高效?我们还是不知道,尽管ChatGPT的成功表明它是相 当高效的。
最终,我们只需注意到ChatGPT使用了近2000亿个权重来完成其 工作一数愤与其接受的训练数据中的词(或标记)的总数相当。 在某些方面,运作良好的“网络的规模”与“训练数据的规模”如 此相似或许令人惊讶(在与ChatGPT结构相似的较小网络中实际观察到的情况也丛如此)。毕竟,ChatGPT内部并没有直接存储来自互联网、书籍等的所有文本。因为ChatGP内部实际上是一堆数 (精度不到10位),它们是所有文本的总体结构的某种分布式编码。
换句话说,我们可以问人类语言的“有效信息”是什么,以及人类 通常用它说些什么。我们有语言样例的原始语料库。在ChatGPT的神经网络中,还有对它们的表示。这些表示很可能远非“算法上最小”的表示,正如下面将讨论的那样。但它们是神经网络可以 轻松使用的表示。在这种表示中,训练数据的“压缩”程度似乎很低。平均而言,似乎只需要不到一个神经网络的权重就可以承载一 个词的训练数据的“信息内容”。
当我们运行ChatGPT来生成文本时,基本上每个权重都需要使用一次。因此,如果有n个权重,就需要执行约n个计算步骤一尽管在实践中,许多计算步骤通常可以在GPU中并行执行。但是, 如果需要约n个词的训练数据来设置这些权重,那么如上所述,我 们可以得出结论:需要约n2个计算步骤来进行网络的训练。这就是为什么使用当前的方法最终需要耗费数十亿美元来进行训练。
在基础训练之外
训练ChatGPT的重头戏是在向其“展示”来自互联网、书籍等的 大量现有文本,但事实证明训练还包括另一个(显然非常重要的) 部分。
一旦根据被展示的原始文本语料库完成“原始训练”,ChatGPT内部的神经网络就会准备幵始生成自己的文本,根据提示续写,等 等。尽管这些结果通常看起来合理,但它们很容易〈特别是在较长 的文本片段中〉以“非类人”的方式“偏离正轨”。这不是通过对 文本进行传统的统计可以轻易检测到的。但是,实际阅读文本的人 很容易注意到。
构建ChatGPT的一个关键思想是,在“被动阅读”来自互联网等的内容之后添加一步:让人类积极地与ChatGPT互动,看看它产生了什么,并且在“如何成为一个好的聊天机器人”方面给予实际反馈。 但是神经网络是如何利用这些反馈的呢?首先,仅仅让人类对神 经网络的结果评分。然后,建立另一个神经网络模型来预测这些评分。现在,这个预测模型可以在原始网络上运行一一本质上像损失函数一样一一从而使用人类的反馈对原始网络进行“调优”。实践中的结果似乎对系统能否成功产生“类人”输出有很大的影响。
总的来说,有趣的是,“原本训练好的网络”似乎只需要很少的“介入”就能在特定方向上有效地进步。有人可能原本认为,为了 让网络表现得好像学到了新东西,就必须为其训练算法、调整权 重,等等。
但事实并非如此。相反,基本上只需要把东西告诉ChatGPT一次——作为提示的一部分——它就可以成功用其生成文本。再次 强调,我认为这种方法有效的事实是理解ChatGPT“实际上在做什 么”以及它与人类语言和思维结构之间关系的重要线索。
它确实有些类人:至少在经过所有预训练后,你只需要把东西告诉它一次,它就能“记住”一至少记住足够长的时间来生成一段文本。这里面到底发生了什么事呢?也许“你可能告诉它的一切都已 经在里面的某个地方了”,你只是把它引导到了正确的位置。但这 似乎不太可能。更可能的是,虽然这些元素已经在里面了,但具体 情况是由类似于“这些元素之间的轨迹”所定义的,而你告诉它的就是这条轨迹。
就像人类一样,如果ChatGPT接收到一些匪夷所思、出乎意料、 完全不符合它已有框架的东西,它就似乎无法成功地“整合”这些 信息。只有在这些信息基本上以一种相对简单的方式依赖于它已有的框架时,它才能够进行“整合”。
值得再次指出的是,神经网络在捕捉信息方面不可避免地存在“算 法限制”。如果告诉它类似于“从这个到那个”等“浅显”的规则, 神经网络很可能能够不错地表示和重现这些规则,并且它“已经掌 握”的语言知识将为其提供一个立即可用的模式。但是,如果试图 给它实际的“深度”计算规则,涉及许多可能计算不可约的步骤, 那么它就行不通了。(请记住,它在每一步都只是在网络中“向前 馈送数据”,除非生成新的标记,否则它不会循环。〉
当然,神经网络可以学习特定的“不可约”计算的答案。但是,一 旦存在可能性的组合数,这种“表查找式”的方法就不起作用了。 因此,就像人类一样,神经网络此时需要使用真正的计算工具。 (没错,Wolfram|Alpha和Wolfram语言就非常适用,因为它们正 是被构建用于“谈论世界中的事物”的,就像语言模型神经网络 —样。)
真正让ChatGPT发挥作用的是什么
人类语言,及其生成所涉及的思维过程,一直被视为复杂性的巅 峰。人类大脑“仅”有约1000亿个神经元(及约100万亿个连 接〉,却能够做到这一切,确实令人惊叹。人们可能会认为,大脑 中不只有神经元网络,还有某种具有尚未发现的物理特性的新层。 但是有了ChatGPT之后,我们得到了一条重要的新信息:一个连 接数与大脑神经元数量相当的纯粹的人工神经网络,就能够出色地生成人类语言。
这仍然是一个庞大而复杂的系统,其中的神经网络权重几乎与当前 世界上可用文本中的词一样多。但在某种程度上,似乎仍然很难相 信语言的所有丰富性和它能谈论的事物都可以被封装在这样一个有 限的系统中。这里面的部分原理无疑反映了一个普遍现象[这个现 象最早在规则30(是本书作者在1983年提出的单维二进制元胞自动机规则。这个简 单、已知的规则能够产生复杂且看上去随机的模式)的例子中变得显而易见]:即使基础规则很简单, 计算过程也可以极大地放大系统的表面复杂性。但是,正如上面讨 论的那样,ChatGPT使用的这种神经网络实际上往往是特别构建的,以限制这种现象(以及与之相关的计算不可约性)的影响,从而使它们更易于训练。
那么,ChatGPT是如何在语言方面获得如此巨大成功的呢?我认为 基本答案是,语言在根本上比它看起来更简单。这意味着,即使是 具有简单的神经网络结构的ChatGPT,也能够成功地捕捉人类语言 的“本质”和背后的思维方式。此外,在训练过程中,ChatGPT已经通过某种方式“隐含地发现” 了使这一切成为可能的语言(和思 维)规律。
我认为,ChatGPT的成功为一个基础而重要的科学事实向我们提供 了证据:它表明我们仍然可以期待能够发现重大的新“语言法则”, 实际上是“思维法则”。在ChatGPT中,由于它是一个神经网络, 这些法则最多只是隐含的但是,如果我们能够通过某种方式使这些法则变得明确,那么就有可能以更直接、更高效和更透明的方式 做出ChatGPT所做的那些事情。
这些法则可能是什么样子的呢?最终,它们必须为我们提供某种 关于如何组织语言及其表达方式的指导。我们稍后将讨论“在 ChatGPT内部”可能如何找到一些线索,并根据构建计算语言的经 验探索前进的道路。但首先,让我们讨论两个早已知晓的“语言法 则”的例子,以及它们与ChatGPT的运作有何关系。
第一个是语言的语法。语言不仅仅是把一些词随机拼凑在一起。相反,不同类型的词之间有相当明确的语法规则。例如,在英语中, 名词的前面可以有形容词、后面可以有动词,但是两个名词通常不 能挨在一起。这样的语法结构可以通过一组规则来(至少大致地)捕捉,这些规则定义了如何组织所谓的“解析树”。
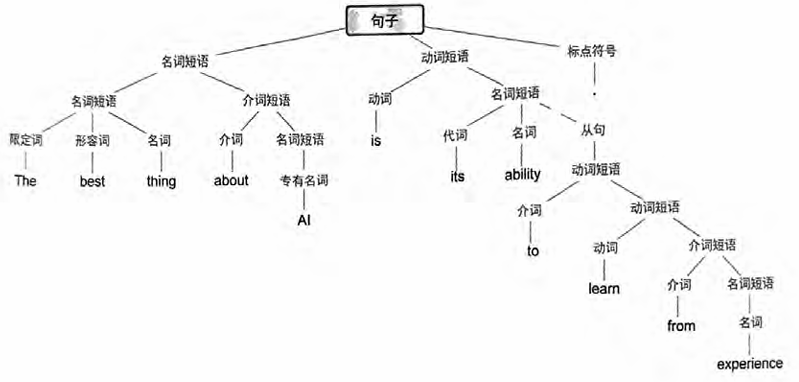
ChatGPT并不明确地“了解”这些规则。但在训练过程中,它隐 含地发现了这些规则,并且似乎擅长遵守它们。这里的原理是什么 呢?在“宏观”上还不清楚。但是为了获得一些见解,也许可以看 看一个更简单的例子。
考虑一种由“(”和“)”的序列组成的“语言”,其语法规定括号 应始终保持平衡,就像下面的解析树—样。
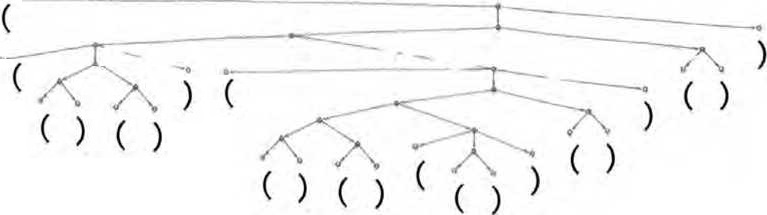
我们能训练神经网络来生成“语法正确”的括号序列吗?在神经 网络中,有各种处理序列的方法,但是这里像ChatGPT一样使用Transformer网络。给定一个简单的Transformer网络,我们可以首 先向它馈送语法正确的括号序列作为训练样例。一个微妙之处(实 际上也出现在ChatGPT的人类语言生成中)是,除了我们的“内 容标记”〔这里是“(”和“)”)之外,还必须包括一个“end”标 记,表示输出不应继续下去了〈即对于ChatGPT来说,已经到达了 “故事的结尾”)。
如果只使用一个有8个头的注意力块和长度为128的特征向量来设置Transformer网络(ChatGPT也使用长度为128的特征向量,但 有96个注意力块,每个块有96个头),似乎不可能让它学会括号语言。但是使用2个注意力块,学习过程似乎会收敛——至少在给 出1000万个样例之后(并且,与Transformer网络一样,展示更多的样例似乎只会降低其性能)。
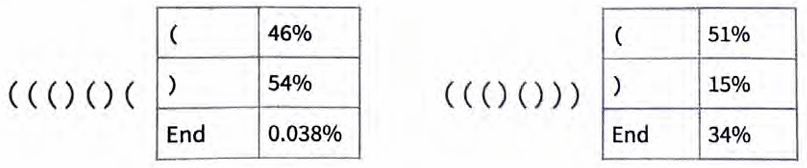
通过这个网络,我们可以做类似于ChatGPT所做的事情,询问括 号序列中下一个符号是什么的概率。
在第一种情况下,网络“非常确定”序列不能在此结束——这很好,因为如果在此结束,括号将不平衡。在第二种情况下,网络 “正确地识别出”序列可以在此结束,尽管它也“指出”可以“重 新开始下一个标记是“(”,后面可能紧接着一个“)”。但糟糕 的是,即使有大约400 000个经过繁重训练的权重,它仍然说下一 个标记是“)”的概率是15%——这是不正确的,因为这必然会导 致括号不平衡。
如果要求网络以最高概率补全逐渐变长的“(”序列,结果将如下所示。

在一定长度内,网络是可以正常工作的。但是一旦超出这个长度, 它就开始出错。这是在神经网络(或广义的机器学习〉等“精确” 情况下经常出现的典型问题。对于人类“一眼就能解决”的问题,
神经网络也可以解决。但对于需要执行“更算法式”操作的问题(例如明确计算括号是否闭合),神经网络往往会“计算过浅”,难 以可靠地解决。顺便说一句,即使是当前完整的ChatGPT在长序列中也很难正确地匹配括号。
对于像ChatGPT这样的程序和英语等语言的语法来说,这意味着什么呢?括号语言是“严谨”的,而且是“算法式”的。而在英语中,根据局部选词和其他提示“猜测”语法上合适的内容更为现 实。是的,神经网络在这方面做得要好得多一一尽管它可能会错 过某些“形式上正确”的情况,但这也是人类可能会错过的。重点 是,语肓存在整体的句法结构,而且它蕴含猎规律性。从某种意义上说,这限制了神经网络滿要学习的内容“多少”。一个关键的“类自然科学”观察结果是,神经网络的Transformer架构,就像ChatGPT中的这个,好像成功地学会了似乎在所有人类语言中都存 在(至少在某种程度上是近似的)的嵌套树状的句法结构。
语法为语言提供了一种约束,但显然还有更多限制。像“Inquisitive electrons eat blue theories for fish”〈好奇的电子为了鱼吃蓝色的理论)这样的句子虽然在语法上是正确的,但不是人们通常会说的 话。ChatGPT即使生成了它,也不会被认为是成功的一因为用 其中的词的正常含义解读的话,它基本上是毫无意义的。
有没有一种通用的方法来判断一个句子是否有意义呢?这方面没有传统的总体理论。但是可以认为,在用来自互联网等处的数十亿个 (应该有意义的)句子对ChatGPT进行训练后,它已经隐含地“发 展出”了一个这样的“理论”。
这个理论会是什么样的呢?它的冰山一角基本上已经为人所知了 2000多年,那就是逻辑。在亚里士多德发现的三段论(syllogistic) 形式中,逻辑基本上用来说明遵循一定模式的句子是合理的,而其 他句子则不合理。例如,说“所有X都是Y。这不是Y,所以它不是X”(比如“所有的鱼都是蓝色的。这不是蓝色的,所以它不是 鱼” 是合理的。就像可以异想天开地想象亚里士多德是通过(“机 器学习式”地)研究大量修辞学例子来发现三段论逻辑一样,也可以想象ChatGPT在训练中通过查看来自互联网等的大量文本能够 “发现三段论逻辑”。(虽然可以预期ChatGPT会基于三段论逻辑等产生包含“正确推理”的文本,但是当涉及更复杂的形式逻辑时, 情况就完全不同了。我认为可以预期它在这里失败,原因与它在括 号匹配上失败的原因相同。〉
除了逻辑的例子之外,关于如何系统地构建(或识别)有合理意义的文本,还有什么其他可说的吗?有,比如像Mad Libs这样使用 非常具体的“短语模板”的东西。但是,ChatGPT似乎有一种更一 般的方法来做到这一点。也许除了“当你拥有1750亿个神经网络 权重时就会这样”,就没有什么别的可以说广。但是我强烈怀疑有 —个更简单、更有力的故事。
意义空间和语义运动定律
之前讨论过,在ChatGPT内部,任何文本都可以被有效地表示为 一个由数组成的数组,可以将其视为某种“语言特征空间”中一 个点的坐标。因此,ChatGPT续写一段文本,就相当于在语言特 征空间中追踪一条轨迹。现在我们会问:是什么让这条轨迹与我 们认为有意义的文本相对应呢?是否有某种“语义运动定律”定 义(或至少限制〕了语言特征空间中的点如何在保持“有意义” 的同时到处移动?
这种语言特征空间是什么样子的呢?以下是一个例子,展示了如果 将这样的特征空间投影到二维平面上,单个词(这里是常见名词) 可能的布局方式。

我们在介绍嵌入时见过一个包含植物词和动物词的例子。这两个例 子都说明了,“语义上相似的词”会被放在相近的位置。
再看一个例子,下图展示了不同词性的词是如何布局的。
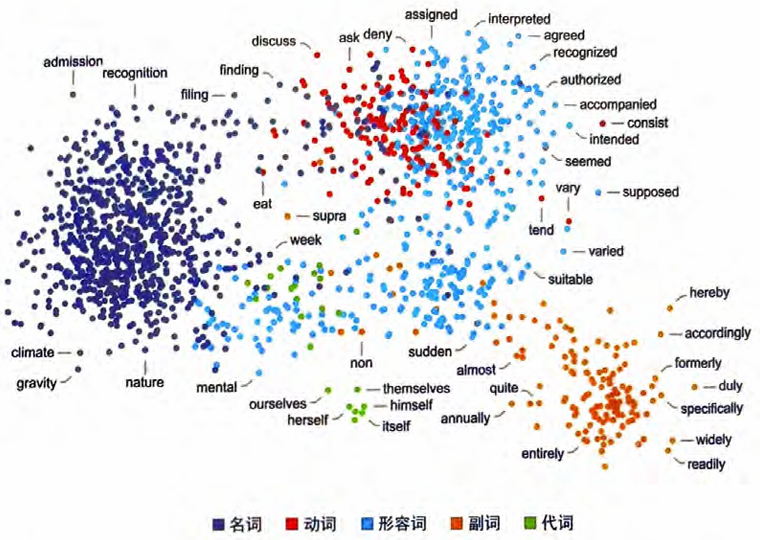
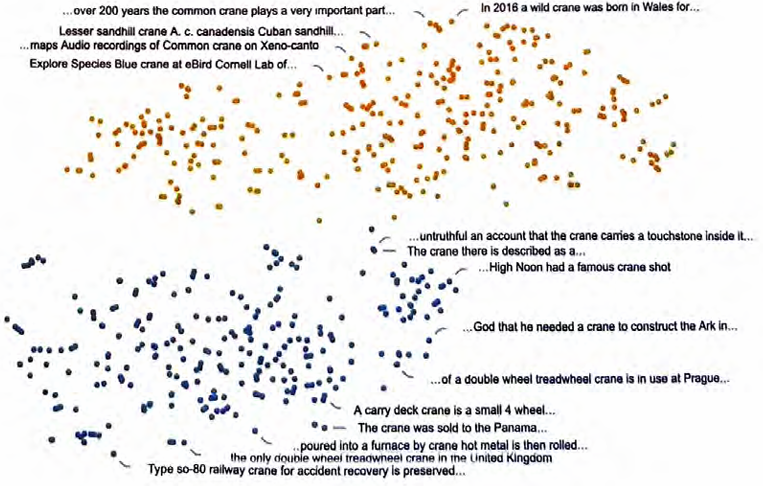
当然,一个词通常不只有“一个意思” ^也不一定只有一种词性 通过观察包含一个词的句子在特征空间中的布局,人们通常可以 “分辨出”它们不同的含义,就像如下例子中的crane这个词(指 的是“鹤”还是“起重机”?)。
看来,至少可以将这个特征空间视为将“意思相近的词”放在这 个空间中的相近位置。但是,我们能够在这个空间中识别出什么 样的额外结构呢?例如,是否存在某种类似于“平行移动”的概 念,反映了空间的“平坦性”?理解这一点的一种方法是看一下相似的词。
即使投影到二维平面上,也通常仍然有一些“平坦性的迹象”,虽然这并不是普遍存在的。
那么轨迹呢?我们可以观察ChatGPT的提示在特征空间中遵循的轨迹,然后可以看到ChatGPT是如何延续这条轨迹的。
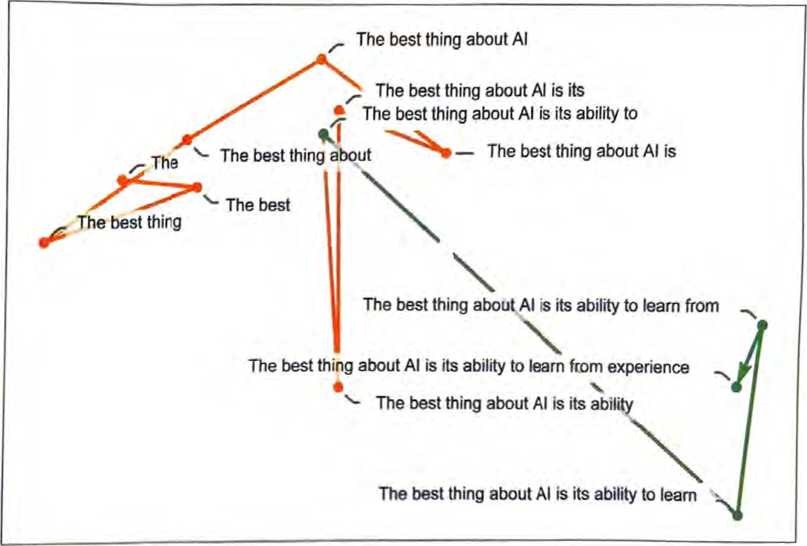
这里无疑没有“几何上显而易见”的运动定律。这一点儿也不令人 意外,我们充分预期到了这会相当复杂。例如,即使存在一个“语 义运动定律”,我们也远不淸楚它能以什么样的嵌入(实际上是 “变量”)来最自然地表述。
在上图中,我们展示了“轨迹”中的几步——在每一步,我们都选择了ChatGPT认为最有可能(“零温度”的情况)出现的词。不过,我们也可以询问在某一点处可能出现的“下一个”词有哪些以及它们出现的概率是多少。
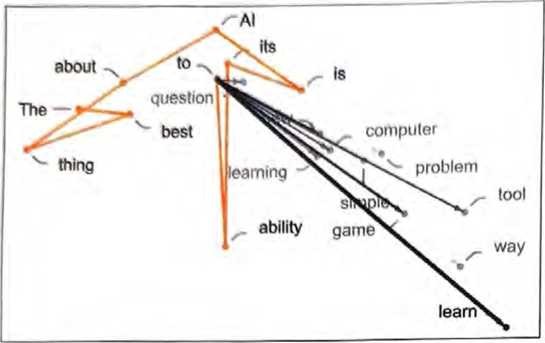
在这个例子中,我们看到的是由高概率词组成的一个“扇形”,它 似乎在特征空间中朝着一个差不多明确的方向前进。如果继续前进 会发生什么?沿轨迹移动时出现的连续“扇形”如下所示。
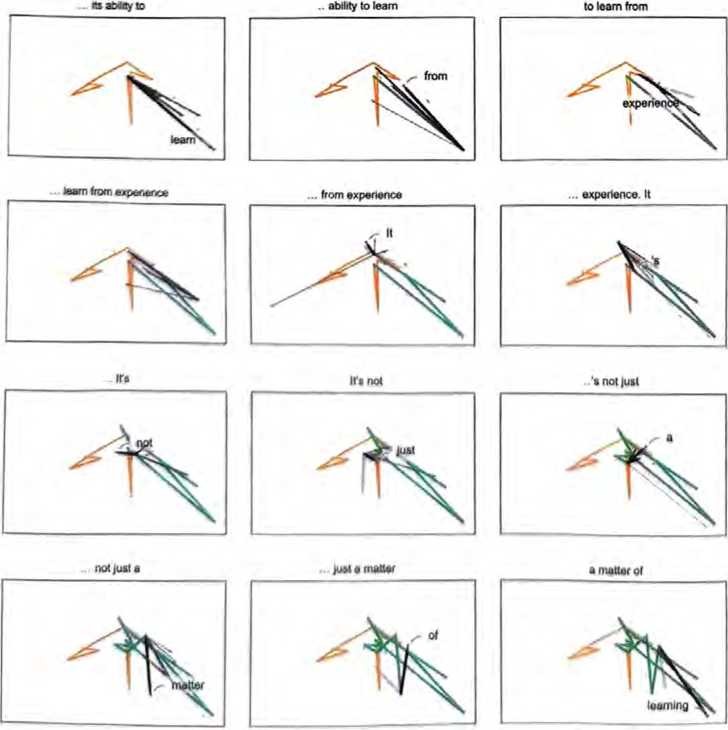
下面是一幅包含40步的三维示意图。
这看起来很混乱,并且没有特别推动通过实证研究“ChatGPT内部的操作”来识别“类似数学物理”的“语义运动定律”。但也许我 们只是关注了“错的变量”〔或者错的坐标系〉,如果关注对的那 —个,就会立即看到ChatGPT正在做“像数学物理一样简单”的 事情,比如沿测地线前进。但目前,我们还没有准备好从它的“内部行为”中“实证解码”ChatGPT已经“发现”的人类语言的“组织”规律。
语义语法和计算语言的力量
产生“有意义的人类语言”需要什么?过去,我们可能认为人类大 脑必不可少。但现在我们知道,ChatGPT的神经网络也可以做得非 常出色。这或许就是我们所能达到的极限,没有比这更简单(或更 易于人类理解〉的方法可以使用了。不过,我强烈怀疑ChatGPT的成功暗示了一个重要的“科学”事实:有意义的人类语言实际上 比我们所知道的更加结构化、更加简单,最终可能以相当简单的规 则来描述如何组织这样的语言。
正如上面提到的,句法语法为如何组织人类语言中属于不同词性的 词提供了规则。但是为了处理意义,我们需要更进一步。一种方法 是不仅考虑语言的句法语法,还要考虑语义语法。
对于句法,我们识别出名词和动词,等等。但对于语义,我们需要 “更精细的分级”。例如,我们可以识别出“移动”的概念和一个“不因位置而改变身份”的“对象”的概念。这些“语义概念”的 例子数不胜数。但对于我们要用的语义语法,只需要一些基本的规 则,基本上来说就是“对象”可以“移动”。关于这可能如何工作, 有很多要说的(其中一些之前已经说过但我在这里只会说几句表明一些潜在前进道路的话。
值得一提的是,即使一句话在语义语法上完全没问题,也不意味着它已经(或者能)在实践中成真。“The elephant traveled to the moon”(大象去了月球)这句话毫无疑问会“通过”我们的语义语法,但 (至少目前)在我们的现实世界中还没有成真,虽然它绝对可以在虚构的世界中成真。 当我们开始谈论“语义语法”时,很快就会问:它的底层是什么? 它假设了什么样的“世界模型”?句法语法实际上只是关于由词构 建语言的。但是语义语法必然涉及某种“世界模型” 一一类似于“骨架”,由实际的词构成的语言可以基于它分层。
直到不久之前,我们可能还是认为(人类)语言将是描述“世界模型”的唯一通用方式。几个世纪前,人们就已经开始针对特定种类 的事物进行形式化,特别是基于数学。但是现在有了一种更通用的形式化方法:计算语言。
是的,这是我四十多年来一直在研究的大型项目(现在体现在Wolfram语言中开发一种精确的符号表示,以尽可能广泛地谈论世界上的事物,以及我们关心的抽象事物。例如,我们有城市、 分子、图像和神经网络的符号表示,还有关于如何计算这些事物的内置知识。
经过几十年的努力,我们已经在许多领域中运用了这种方法。但是过去,我们并没有特别用其处理“日常话语”。在“我买了两斤苹 果”中,我们可以轻松地表示“两斤苹果”(并进行有关的营养和其他计算),但是(还)没有找到“我买了”的符号表示。
这一切都与语义语法的思想有关一~目标是拥有一个对各种概念通用的符号“构造工具包”,用于对什么可以与什么组合在一起给出规则,从而对可以转化为人类语言的“流”给出规则。
假设我们有这种“符号话语语言”,我们会用它做什么呢?首先可 以生成“局部有意义的文本”。但最终,我们可能想要更有“全局 意义”的结果一一这意味着“计算”更多实际存在或发生于世界 (或某个与现实一致的虚构世界)中的事情。
在Wolfram语言中,我们已经拥有了关于许多种事物的大量内置 计算知识。但如果要建立一种完整的符号话语语言,我们还需要纳 入关于世界上一般事物的额外“计算方法”(calculi):如果一个物 体从A移动到B,然后从B移动到C,那么它就从A移动到了C,等等。
我们不仅可以用符号话语语言来做“独立的陈述”,而且可以用它 来问关于世界的问题,就像对Wolfram|Alpha所做的那样。此外, 也可以用它来陈述我们“想要实现”的事情,这可能需要一些外部 激活机制;还可以用它来做断言一也许是关于实际世界的,也许 是关于某个我们正在考虑的(无论是虚构还是其他的)特定世界的。 人类语言是不精确的,这主要是因为它没有与特定的计算实现相“结合”,其意义基本上只由其使用者之间的“社会契约”定义。 但是,计算语言在本质上具
有一定的精确性,因为它指定的内容最 终总是可以“在计算机上毫无歧义地执行”。人类语言有一定的模 糊性通常无伤大雅。(当我们说“行星”时,是否包括外行星呢? 等等。但在计算语言中,我们必须对所做的所有区别进行精确和 清晰的说明。
在计算语言中,利用普通的人类语言来创造名称通常很方便。但是 这些名称在计算语言中的含义必须是精确的,可能涵盖也可能不涵 盖典型人类语言用法中的某些特定内涵。
如何确定适用于一般符号话语语言的“本体论”以)呢? 这并不容易。也许这就是自亚里士多德2000多年前对本体论做出 原始论述以来,在这些方面几乎没有什么进展的原因。但现在,我 们已经知道了有关如何以计算的方式来思考世界的许多知识,这确 实很有帮助(从我们的Physics Project和ruliad[本书作者创造的概念,即所有可能的计算过程的纠缠上限:以各种可能的方式遵循所有可能的计算规则的结果。详见文章“the concept of the ruliad”]思想中得到“基本 的形而上学”也无妨)。
所有这些在ChatGPT中意味着什么呢?在训练中,有效 地“拼凑出”了一定数量(相当惊人)的相当于语义语法的东西。 它的成功让我们有理由认为,构建在计算语言形式上更完整的东西 是可行的。与我们迄今为止对ChatGPT内部的理解不同的是,我 们可以期望对计算语言进行设计,使其易于被人类理解。
当谈到语义语法时,我们可以将其类比于三段论逻辑。最初,三段 论逻辑本质上是关于用人类语言所表达的陈述的一组规则。但是, 当形式逻辑被发展出来时(没错,在2000多年之后〉,三段论逻 辑最初的基本结构也可以用来构建巨大的“形式化高塔”,能用于 解释(比如〉现代数字电路的运作。因此,我们可以期待更通用的 语义语法也会如此。起初,它可能只能处理简单的模式,例如文 本。但是,一旦它的整体计算语言框架被建立起来,我们就可以期 待用它来搭建“广义语义逻辑”的高塔,让我们能够以精确和形式 化的方式处理以前接触不到的各种事物(相比之下,我们现在只能 在“地面层”处理人类语言,而且带有很大的模糊性 我们可以将计算语言一一和语义语法一一的构建看作一种在表示 事物方面的终极压缩。因为它使我们不必(比如)处理存在于普通 人类语言中的所有“措辞”,就能够谈论可能性的本质。可以认为 ChatGPT的巨大优势与之类似:因为它也在某种意义上“钻研”至|』 了,不必考虑可能的不同措辞,就能“以语义上有意义的方式组织 语言”的地步。
如果我们将ChatGPT应用于底层计算语言,会发生什么呢?计算 语言不仅可以描述可能的事物,而且还可以添加一些“流行”之 感,例如通过阅读互联网上的所有内容做到。但是,在底层,使用 计算语言操作意味着像ChatGPT这样的系统可以立即并基本地访 问能进行潜在不可约计算的终极工具。这使ChatGPT不仅可以生 成合理的文本,而且有望判断文本是否实际上对世界(或其所谈论 的任何其他事物)做出了“正确”的陈述。
那么ChatGPT到底在做什么? 它为什么能做到这些?
ChatGPT的基本概念在某种程度上相当简单:首先从互联网、书籍等获取人类创造的海量文本样本,然后训练一个神经网络来生成 “与之类似”的文本。特别是,它能够从“提示”开始,继续生成 “与其训练数据相似的文本”。
正如我们所见,ChatGPT中的神经网络实际上由非常简单的元素组 成,尽管有数十亿个。神经网络的基本操作也非常简单,本质上是 对于它生成的每个新词(或词的一部分),都将根据目前生成的文 本得到的输入依次传递“给其所有元素一次”〔没有循环等〕。
值得注意和出乎意料的是,这个过程可以成功地产生与互联网、书 籍等中的内容“相似”的文本。ChatGPT不仅能产生连贯的人类语言,而且能根据“阅读”过的内容来“循着提示说一些话”。它并不总是能说出“在全局上有意义”(或符合正确计算)的话,因为 (如果没有利用Wolffram|Alpha的“计算超能力”〉它只是在根据训 练材料中的内容“听起来像什么”来说出“听起来正确”的话。
ChatGPT的具体工程非常引人注目。但是,(至少在它能够使用外 部工具之前)ChatGPT“仅仅”是从其积累的“传统智慧的统计 数据”中提取了一些“连贯的文本线索”。但是,结果的类人程度 已经足够令人惊讶了。正如我所讨论的那样,这表明了一些至少 在科学上非常重要的东西:人类语言及其背后的思维模式在结构 上比我们想象的更简单、更“符合规律”。ChatGPT已经隐含地发 现了这一点。但是我们可以用语义语法、计算语言等来明确地揭 开它的面纱。
在生成文本方面表现得非常出色,结果通常非常类似于人类创作的文本。这是否意味着ChatGPT的工作方式像人类的大脑 一样?它的底层人工神经网络结构说到底是对理想化大脑的建模。 当人类生成语言时,许多方面似乎非常相似。
当涉及训练(即学习)时,大脑和当前计算机在“硬件”(以及一 些未开发的潜在算法思想)上的不同之处会迫使ChatGPT使用一 种可能与大脑截然不同的策略(在某些方面不太有效率还有一 件事值得一提:甚至与典型的算法计算不同,ChatGPT内部没有 “循环”或“重新计算数据”。这不可避免地限制了其计算能力——即使与当前的计算机相比也是如此,更谈不上与大脑相比了。
我们尚不清楚如何在“修复”这个问题的同时仍然让系统以合理的 效率进行训练。但这样做可能会使未来ChatGPT能够执行更多“类似大脑的事情”。当然,有许多事情大脑并不擅长,特别是涉及不可约计算的事情。对于这些问题,大脑和像 ChatGPT 这样的东西都必须寻求“外部工具”,比如 Wolfam 语言的帮助。
但是就目前而言,看到 ChatGPT已经能够做到的事情是非常令人兴奋的。在某种程度上,它是一个极好的例子,说明了大量简单的计算元素可以做出非凡、惊人的事情。它也为我们提供了 2000多年以来的最佳动力,来更好地理解人类条件(human condition)的核心特征——人类语言及其背后的思维过程——的本质和原则。
第二篇 利用Wolfram|Alpha为ChatGPT赋予计算知识超能力
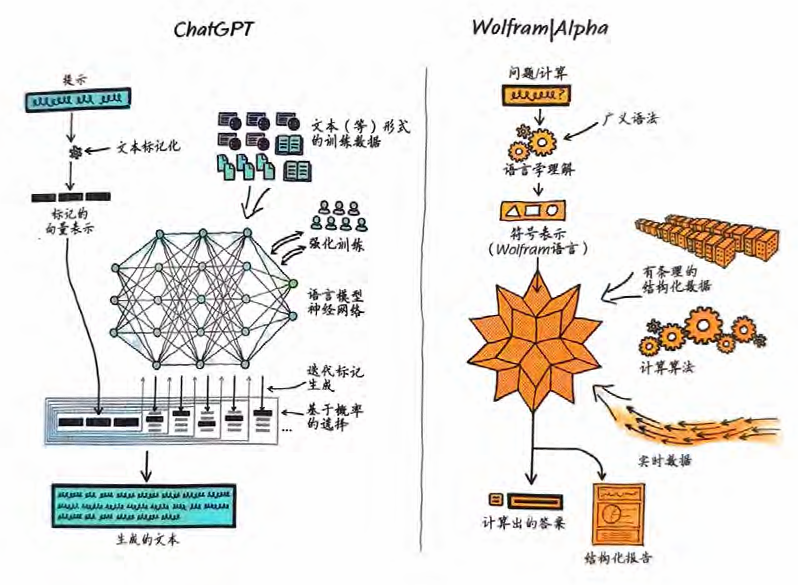
ChatGPT和Wolfram|Alpha
当事物不知怎么突然开始“发挥作用”时,总是让人惊叹不已。 这在2009年的Wolfram|Alpha上发生过,在2020年的Physics Project上也发生过。现在,它正在ChatGPT上发生。
我已经研究神经网络技术很长时间了〈实际上已经有43年了〉。即 使目睹了过去几年的发展,我仍然认为ChatGPT的表现非常出色。 最终,突然出现了一个系统,可以成功地生成关于几乎任何东西的 文本,而且非常类似于人类可能编写的文本。这非常令人佩服,也 很有用。而且,正如我讨论过的那样,我认为它的成功可能向我们 揭示了人类思维本质的一些基本规律。
虽然ChatGPT在自动化执行主要的类人任务方面取得了显著的成 就,但并非所有有用的任务都是如此“类人”的。一些任务是更加 形式化、结构化的。实际上,我们的文明在过去几个世纪中取得的 一项伟大成就就是建立了数学、精密科学一最重要的是计算一 的范式,并且创建了一座能力高塔,与纯粹的类人思维所能达到的 高度完全不同。
我自己已经深度参与计算范式的研究多年,追求建立一种计算语 言,以形式化符号的方式来表示世界中尽可能多的事物。在此过程 中,我的目标是建立一个系统,用于“在计算上辅助”和增强人类 想要做的事情。虽然我本人只能用人类的方式来思考事物,但我 也可以随时调用Wolfram语言和Wolfram|Alpha来利用一种独特的 “计算超能力”做各种超越人类的事情。
这是一种非常强大的工作方式。重点是,它不仅对我们人类很重 要,而且对类人AI 同样(甚至 更)重要——可以直接为其赋予计算知识超能力,利用结构化计算和结构化知识的非类人力跫。
尽管我们才刚刚开始探索这对ChatGPT意味着什么,但很明显, 惊喜是可能出现的。虽然Wolfram|Alpha和ChatGPT所做的事情 完全不同,做事的方式也完全不同,但它们有一个公共接口:自 然语言。这意味着可以像人类一样与Wolfram|Alpha“交 谈”,而Wolfram|Alpha会将它从ChatGPT获得的自然语言转换为 精确的符号计算语言,从而应用其计算知识能力。
几十年来,对AI的思考一直存在着两极分化:ChatGPT使用的 “统计方法”,以及实际上是Wolfram|Alpha的起点的“符号方法”。现在,由于有了 ChatGPT的成功以及我们在使Wolfram|Alpha理解自然语言方面所做的所有工作,终于有机会将二者结合起来,发 挥出比单独使用任何一种方法都更强大的力量。
一个简单的例子
ChatGPT本质上是一种生成语言输出的系统,其输出遵循来自互联 网和书籍等的训练材料中的“模式”。令人惊奇的是,输出的类人 特征不仅体现在小范围内,而且在整个文章中都很明显。它可以表 达连贯的内容,通常以有趣和出人意料的方式包含它所学的概念 产生的内容始终是“在统计学上合理”的,至少是在语言层面上合 理的。尽管它的表现非常出色,但这并不意味着它自信给出的所有 事实和计算都一定是正确的。
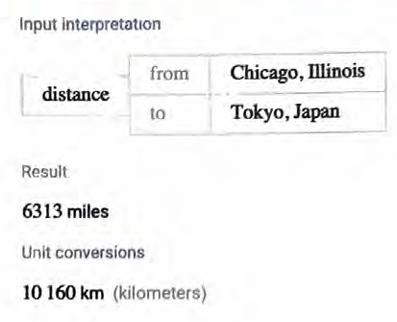
下面是我刚刚注意到的一个例子(ChatGPT具有内在的随机性,因 此如果你尝试问相同的问题,可能会得到不同的答案)。

听起来相当有说服力。但是事实证明它是错误的,因为Wolfram|Alpha可以告诉我们如下答案。

当然,这显得不太公平,因为这个问题正是Wolfram|Alpha擅长的 问题类型:可以基于其结构化、有条理的知识进行精确计算。
有趣之处是,我们可以想象让Wolfram|Alpha自动帮助ChatGPT。 可以通过编程向Wolfram|Alpha提问(也可以使用Web API等)。

现在再次向ChatGPT提问,并附上此结果。

ChatGPT非常礼貌地接受了更正。如果你再次提出该问题,它会给出正确的答案。显然,可以用一种更精简的方式处理与Wolfram|Alpha的交流,但是看到这种非常简单的纯自然语言方法已经基本奏效也 很令人高兴。
不过,为什ChatGPT一开始会犯这个错误呢?如果它在训练时 从某个地方(例如互联网上)看到了芝加哥和东京之间的具体距 离,它当然可以答对。但在本例中,仅仅依靠神经网络能轻松完成 的泛化(例如对于许多城市之间距离的许多示例的泛化)并不够,还需要一个实际的计算算法。
Wolfram|Alpha的处理方式则截然不同。它接受自然语言,然后 (假设可能的话)将其转换为精确的计算语言(即Wolfram语言),在本例中如下所示。

城市的坐标和计算距离的算法是Wolfram语言内置的计算知识的一部分。是的,Wolfram语言拥有大量内置的计算知识——这是我们几十年的工作成果,我们精心梳理了不断更新的海泔数据,实现 (而且经常发明)了各种方法、模型和算法——并且系统地为一切构建了一整套连贯的计箅语言。
再举几个例子
ChatGPT和Wolfram|Alpha的工作方式截然不同,各有优势。为了理解ChatGPT可以如何利用Wolfram|Alpha的优势,让我们讨论ChatGPT本身并不能完全回答正确的一些情况。ChatGPT像人类 一样,经常在数学领域遇到困难。

很有趣的文章式回答,但实际结果是错误的。


如果让ChatGPT “咨询”Wolfram|Alpha,它当然可以得到正确的答案。
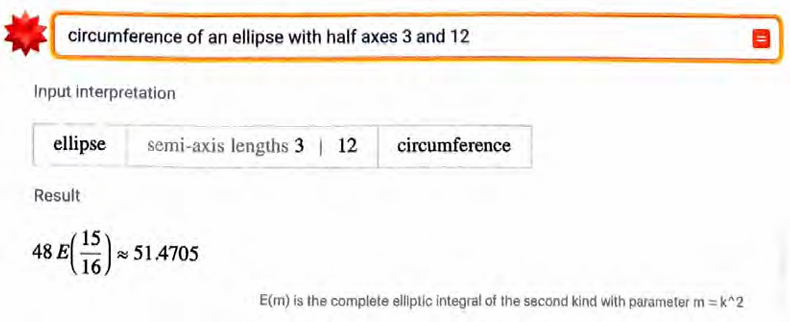
让我们尝试一些稍微复杂的问题。

乍一看,这个结果似乎很棒,我很容易相信它。然而,事实证明它是错误的,因为可以告诉我们如下答案。
因此,使用(不能咨询Wolfram|Alpha的)ChatGPT做数学作业可能不是一个好主意。它可以给你一个看似非常可信的答案。

但是如果ChatGPT没有“真正理解数学”,就基本上不可能可靠地得出正确答案。所以,答案又是错误的。

ChatGPT甚至可以为“它得出答案的方式”〈尽管并不是它所“做” 的真正方式)编造一个非常像样的解释。此外,迷人(和有趣)的是,它给出的解释里存在不理解数学的人类可能会犯的错误。

在各种各样的情况下,“不理解事物的含义”都可能会引起麻烦。

听起来颇有说服力,但不正确。
ChatGPT似乎在某处正确地学习了这些基础数据,但它并没有充分 “理解数据的含义”以正确地排列这些数字。

是的,可以找到一种方法来“修复这个特定的bug”。但问题在于, 像ChatGPT这样基于生成语言的AI系统的基本思想并不适用于需要执行结构化计算任务的情况。换句话说,需要“修复”几乎无穷 多的“bug”,才能追赶上Wolfram|Alpha以其结构化方式所能实现 的几乎无穷小的成就。
“计算链”越复杂,就越有可能需要调用Wolfram|Alpha以来正确处 理。对于下面的问题,ChatGPT给出了一个相当混乱的答案。

正如Wolfram|Alpha告诉我们的那样,ChatGPT的结论并不正确(就像它自己在某种程度上“已经知道”的)。
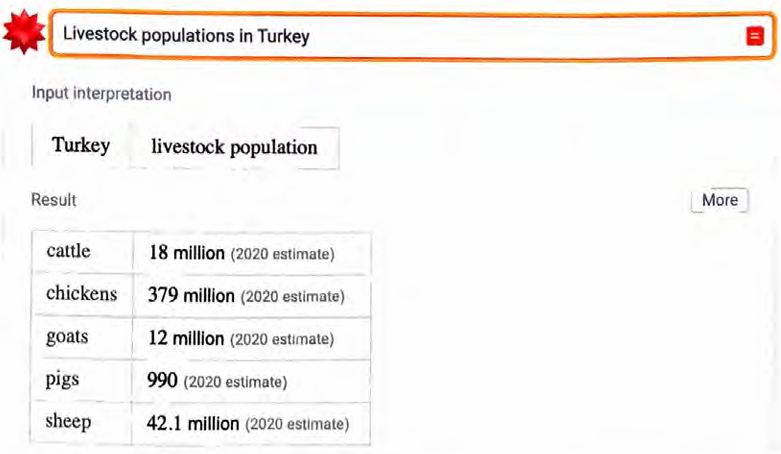
每当涉及特定的(例如数量)数据时,即使是相当原始的形式,也 往往更适合用Wolfram|Alpha处理。以下这个例子受到了长期以来 最受喜爱的Wolfram|Alpha测试查询“How many turkeys are there in Turkeys?”〈土耳其有多少只火鸡〉的启发。

这(一开始)看起来完全有道理,甚至引用了相关的来源。然而事 实证明,这些数据基本上只是“捏造”的。
不过,非常好的一点是,ChatGPT可以轻松地“请求事实来做检查”。

现在将这些请求通过Wolfram|Alpha API进行馈送。

现在我们可以注入这些数据,要求ChatGPT修正其原始回答(甚至以粗体显示它所做的修正)。

当涉及实时(或依赖位置等的)数据或计算时,“注入事实”的能力特别好。ChatGPT不会立即回答下面这个问题。

下面是一些相关的Wolfram|Alpha API输出。

如果将其输入ChatGPT,它会生成漂亮的文章式结果。

有时,计算系统和类人系统之间会有有趣的相互作用。下面是一个向Wolfram|Alpha提出的相当异想天开的问题,而它甚至会询问你是否想要“soft-serve ice cream”(软冰激凌)。
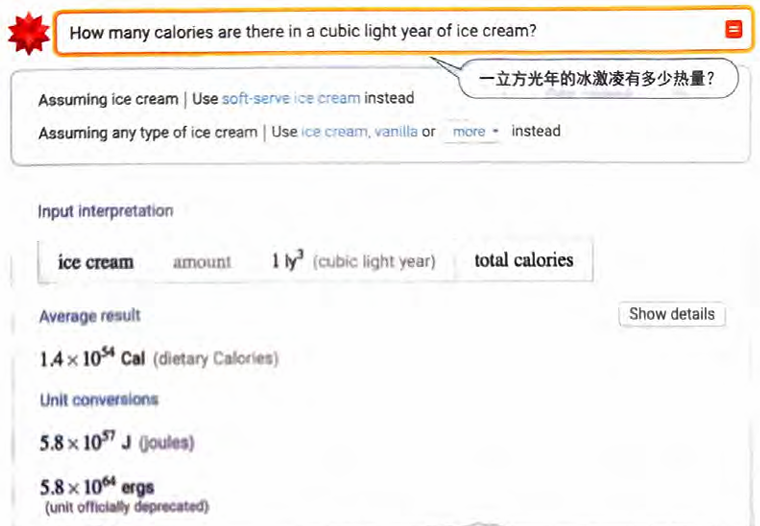
ChatGPT最开始对于“volume”(体积)的概念有些困惑。

但后来它似乎“意识到”那么多冰激凌是相当愚蠢的。
A cubic light year is an extremely large unit of volume. In fact, it is so large that it is not possible to fit any known substance, including ice cream, into a volume of this size.
For reference, a light year is a unit of distance that is equal to the distance that light travels in one year. The distance that light travels in one year is approximately 5.88 trillion miles (9.46 trillion kilometers).
Given the size of a light year, it is clear that a cubic light year is an impossibly large unit of volume. Therefore, it is not possible to calculate the number of calculate in a cubic light year of ice cream, as there is simply no way to fit that much ice cream into a single volume.
前方的路
机器学习是一种强大的方法,特别是在过去十年中,它取得了一些非凡的成功——ChatGPT是最新的成功案例。除此之外,还有图 像识别、语音转文字、语言翻译……在每个案例中,都会跨越一个门槛一一通常是突然之间。一些任务从“基本不可能”变成了“基本可行”。
但结果从来不是“完美”的。也许有的东西能够在95%的时间内运作良好。但是不论怎样努力,它的表现在剩下的5%时间内仍然 难以捉摸。对于某些情况来说,这可能被视为失败。但关键在于, 在各种重要的用例中,95%往往就“足够好了”。原因也许是输出 是一种没有“正确答案”的东西,也许是人们只是在试图挖掘一些 可能性供人类(或系统算法)选择或改进。
拥有数百亿参数的神经网络一次一个标记地生成文本,能够做到ChatGPT所能做的事情,这着实是非同凡响的。鉴于这种戏剧性、 意想不到的成功,人们可能会认为,如果能够“训练一个足够大的网络”,就能够用它来做任何事情。但事实并非如此。关于计算的 基本事实,尤其是计算不可约的概念,表明它最终是无法做到的。
不过不要紧,重点在于我们在机器学习的实际历史中看到的:会取得(像ChatGPT这样的)重大突破,进步不会停止。更重要的是, 我们会发现能做之事的成功用例,它们并未因不能做之事受阻。
虽然“原始ChatGPT”可以在许多情况下帮助人们写作、提供建议 或生成对各种文档或交流有用的文本,但是当必须把事情做到完美 时,机器学习并不是解决问题的方法一就像人类也不是一样。
这正是我们在以上例子中看到的。ChatGPT在“类人的部分”表 现出色,因为其中没有精确的“正确答案”。但当它被“赶鸭子上 架”、需要提供精确的内容时,往往会失畋,这些例子要表达的重 点是,有一种很好的方法可以解决该问题一将ChatGPT连接到Wolfram|Alpha以利用其全部的计算知识”超能力”。
在Wolfram|Alpha内部,一切都被转换为计算语言,转换为精确的Wolfram语言代码。这些代码在某种程度上必须是“完美”的,才 能可靠地使用。关键是,ChatGPT无须生成这些代码。它可以生成 自己常用的自然语言,然后由Wolfram|Alpha利用其自然语言理解能力转换为精确的Wolfram语言。
在许多方面,可以说ChatGPT从未“真正理解”过事物,它只 “知道如何产生有用的东西”。但是购丨加咖则完全不同。因 为一旦Wolfram|Alpha将某些东西转换为加Wolfram语言,我们就 拥有了它们完整、精确、形式化的表示,可以用来可靠地计算事 物。不用说,有很多“人类感兴趣”的事物并没有形式化的计算表 示一尽管我们仍然可以用自然语言谈论它们,但是可能不够准 确。对于这些事物,ChatGPT只能靠自己,而且能凭借自己的能力 做得非常出色。
就像我们人类一样,ChatGPT有时候需要更形式化和精确的“助力”。重点在于,它不必用“形式化和精确”的语言表达自己, 因为Wolfram|Alpha可以用相当于ChatGPT母语的自然语言进行沟通。当把自然语言转换成自己的母语——Wolfram语言时,Wolfram|Alpha会负责“添加形式和精度”。我认为这是一种非常好 的情况,具有很大的实用潜力。
这种潜力不仅可以用于典型的聊天机器人和文本生成应用,还能扩 展到像数据科学或其他形式的计算工作(或编程)中。从某种意义 上说,这是一种直接把ChatGPT的类人世界和Wolfram语言的精确计算世界结合起来的最佳方式。
ChatGPT能否直接学习Wolfram语言呢?答案是肯定的,事实上 它已经开始学习了。我十分希望像ChatGPT这样的东西最终能够 直接在Wolfram语言中运行,并且因此变得非常强大。这种有趣而 独特的情况之所以能成真,得益于Wolfram语言的如下特点:它是 一门全面的计算语言,可以用计算术语来广泛地谈论世界上和其他地方的事物。
Wolfram语言的总体概念就是对我们人类的所思所想进行计算上的 表示和处理。普通的编程语言旨在确切地告诉计算机要做什么,而 作为一门全面的计算语言,Wolfram语言涉及的范围远远超出了这 —点。实际上,它旨在成为一门既能让人类也能让计算机“用计算思维思考”的语言。
许多世纪以前,当数学符号被发明时,人类第一次有了“用数学思 维思考”事物的一种精简媒介。它的发明很快导致了代数、微积分和最终所有数学科学的出现。Wolfram语言的目标则是为计算思维 做类似的事情,不仅是为了人类,而且是要让计算范式能够开启的 所有“计算XX学”领域成为可能。
我个人因为使用Wolfram语言作为“思考语言”而受益匪浅。过 去几十年里,看到许多人通过Wolfram语言“以计算的方式思考”而取得了很多进展,真的让我喜出望外。那么ChatGPT呢? 它也可以做到这一点,只是我还不确定一切将如何运作。但可以肯定的是,这不是让ChatGPT学习如何进行Wolfram语言已经掌握的计算,而是让ChatGPT学习像人类一样使Wolfram语言,让ChatGPT用计算语言(而非自然语言)生成“创造性文 章”,等等。
我在很久之前就讨论过由人类撰写的计算性文章的概念,它们混合 使用了自然语言和计算语言。现在的问题是,ChatGPT能否撰写这些文章,能否使用Wolfram语言作为一种提供对人类和计算机而言都“有意义的交流”的方式。是的,这里存在一个潜在的有趣的反馈循环,涉及对Wolfram语言代码的实际执行。但至关重要的是Wolfram语言代码所代表的“思想”的丰富性和“思想”流——与普通编程语言中的不同,更接近ChatGPT在自然语言中“像魔法 一样”处理的东西。
换句话说,Wolfram语言是和自然语言一样富有表现力的,足以用 来为ChatGPT编写有意义的“提示”。没错,Wolfram语言代码可 以直接在计算机上执行。但作为ChatGPT的提示,它也可以用来 “表达”一个可以延续的“想法”。它可以描述某个计算结构,让 ChatGPT “即兴续写”人们可能对于该结构的计算上的说法,而且 根据它通过阅读人类写作的大量材料所学到的东西来看,这“对人 类来说将是有趣的”。
ChatGPT的意外成功突然带来了各种令人兴奋的可能性。就目前而言,我们能马上抓住的机会是,通过Wolfram|Alpha赋予ChatGPT计算知识超能力。这样,ChatGPT不仅可以产生“合理的类人输 出”,而且能保证这些输出利用了封装在Wolfram|Alpha和Wolfram语言内的整座计算和知识高塔。
相关资源
文章《ChatGPT在做什么?它为何能做到这些?》(What Is ChatGPT Doing…and Why Does It Work)
本文作者文章《初中生能看懂的机器学习》:介绍机器学习的基本概念
图书《机器学习入门》:一本关于现代机器学习的指南,包含可运行的代码
网站“Wolfram机器学习”:阐释Wolfram语言中的机器学习能力
Wolfram U上的机器学习课程:交互式的机器学习课程,适合不同层次的学生学习
文章《如何与AI交流?》(本文作者2015年的一篇短文,探讨了如何使用自然 语言和计算语言与AI交流)
Wolfram语言
Wolfram|Alpha
发表回复
要发表评论,您必须先登录。